
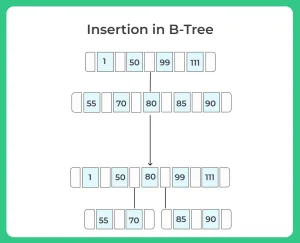
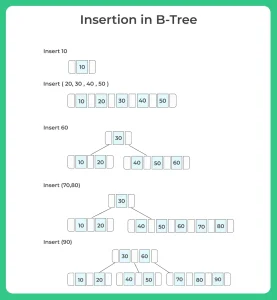
Insertion in B-Tree




Get Hiring Updates right in your inbox from PrepInsta
Login/Signup to comment