
Partition Allocation Method in Operating System
Partition Allocation Method in Operating System
The memory systems developed in early 1990 had a contiguous(continuous) memory available for storing different files one example of such traditional OSes is MS-Dos. But, in Partition Allocation Method in Operating System that have been developed that do not have a contiguous memory space available for files. In fact they are divided into blocks of different sizes.

Partition Allocation Methods in OS
The memory systems developed in early 1990 had a contiguous(continuous) memory available for storing different files one example of such traditional OSes is MS-Dos.
But, new systems that have been developed do not have a contiguous memory space available for files. In fact they are divided into blocks of different sizes.
This was done to avoid complete memory corruption if a file is infected. If memory is divided into blocks corrupted file will only infect that memory block in which its stored.
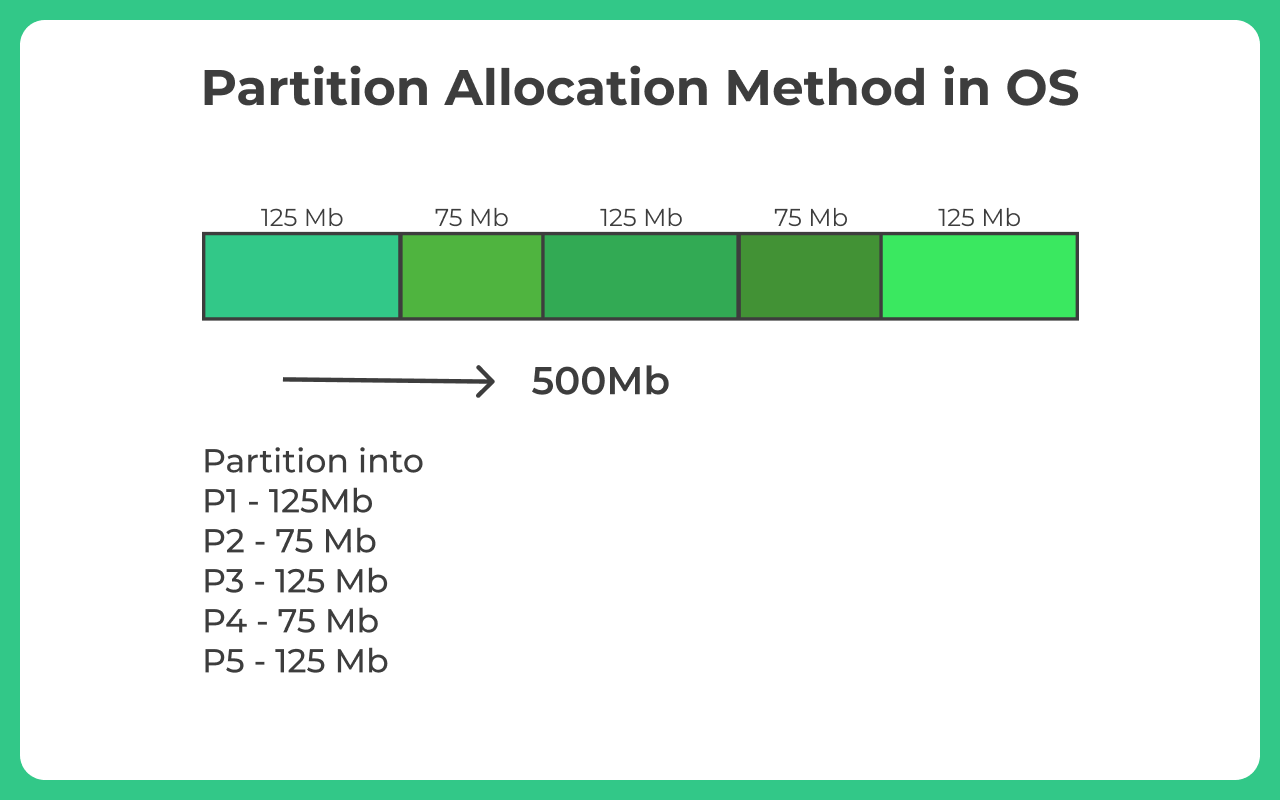

Example of Memory Partitioning
For example, a 500Mb memory may be (equally or unequally) divided to blocks 5 blocks of 100Mb each.
Or unequally as in 5 blocks of 125mb, 75mb, 125mb, 75mb, 125mb respectively.
The main memory must accommodate –
- Operating system
- User processes
- Operating System Processes
For a partitioned memory available in modern systems, we need different algorithms to decide most which processes must use which memory block while maintaining the most efficient use of these memory block.
We therefore need to allocate different parts of the main memory in the most efficient way possible.
Memory Partitioning Algorithms
The main four partition allocation schemes are listed below:-
- First Fit
- Best Fit
- Worst Fit
- Next Fit
Overview
There are two major divisions one for operating system residing and other for allocating processes.
- OS memory can’t be altered in a direct by way by user.
- Process memory is managed by OS to perform processes.
One of the simplest methods for memory allocation
- Divide memory into several fixed-sized partitions.
- Each partition may contain exactly one process.
- When a partition is free, a process is selected from the input queue and is loaded into the free partition.
- When the process terminates, the partition becomes available for another process.
- The operating system keeps a table indicating which parts of memory are available and which are occupied using a table.
- Finally, when a process arrives and needs memory, a memory section large enough for this process is provided.
The following are used to choose process memory allocation –
- First Fit
- Best Fit
- Worst Fit
- Next Fit
We will use the following memory block to demonstrate each process –
[table id=366 /]
First Fit
For a process P1, whichever first partition (starting from the top) is large enough to fit the current process, gets the process allocated to itself.
See Example at –
Partitioned Blocks –
[table id=366 /]
Jobs –
[table id=367 /]
- Job 1 (size – 100k)
- Can’t fit in block 1 as 50k(block size) <100k (job size)
- Goes to block 2 as can fit in block 2 as 200K > 100K (Size of block more than size of process)
- 100K remains empty in this block now.
- Job 2 (size 10K)
- Goes to block 1 as 10K < 100k
- Job 3 (size 35 K)
- Can fit Block 1 but block 1 is not empty(used by job2)
- Can’t fit and also Block 2 not empty
- Can fit in block 3 Goes to block 3
- Job 4
- Goes to block 4
- Job 5
- All blocks 1 to 4 are occupied
- Can’t fit in block 5 as size is more than block
So block 5 remains unused. and Job5 has to wait until other processes finish.
[table id=368 /]
Facts
First-fit memory allocation is faster in making allocation but leads to memory waste.
If the chosen block is significantly larger than that requested, then it is usually split, and the remainder added to the list as another free block.
The first fit algorithm performs reasonably well, as it ensures that allocations are quick. When recycling free blocks, there is a choice as to where to add the blocks to the free list—effectively in what order the free list is kept
Best Fit
Best-fit memory allocation makes the best use of memory space but slower in making the allocation.
For example let us suppose that we have 4 partitions of size 16,12,8, 4 available with us. The list of available partitions is in the order of their availability . Thus if we get an incoming request for the memory size of 6.
Although the first available block that is of size 16 can accommodate the request greedily then also it won’t. Block size of 16 would have been allocated if the algorithm would have been the first fit which we will discuss later.
In this case block of 8 which is best fit for the incoming process request is allocated.
Thus, in short words – Allocate the process to the partition which is first smallest sufficient partition among the free available partition.
Example
- Job 1 (size – 100k)
- Block 1 size(50k) – 100k = Negative value
- Block 2 size(200k) – 100k = 100k
- Block 3 size(70k) – 100k = Negative value
- Block 4 size(115k) – 100k = 15k
- Block 5 size(15k) – 100k = Negative value
- Goes to block 4 as 15K is best case
- Job 2 (size – 10k)
- Block 1 size(50k) – 10k = 40k
- Block 2 size(200k) – 10k = 190k
- Block 3 size(70k) – 10k = 60k
- Block 4 occupied by job 1
- Block 5 size(15k) – 10k = 5K
- Goes to block 5 as 5K is best case
- Job 3 (size – 35k)
- Block 1 size(50k) – 35k = 15k
- Block 2 size(200k) – 35k = 165k
- Block 3 size(70k) – 35k = 35k
- Block 4 occupied by job 1
- Block 5 occupied by job 2
- Goes to block 1 as 15K is best case
- Job 4 (size – 15k)
- Block 1 occupied by job 3
- Block 2 size(200k) – 15k = 185k
- Block 3 size(70k) – 15k = 55k
- Block 4 occupied by job 1
- Block 5 occupied by job 2
- Goes to block 3 as 55k is best case
- Job 5 (size – 23k)
- Block 1 occupied by job 3
- Only option. size of block (200k) > size of job(23k)
- Block 3 occupied by job 4
- Block 4 occupied by job 1
- Block 5 occupied by job 2
- Goes to block 2 as 100K is worst case
[table id=371 /]
Worst Fit
Worst-fit memory allocation is opposite to best-fit. It allocates free available block to the new job and it is not the best choice for an actual system It selects the largest available hole in memory that can fit a needed segment, so as to leave a large hole for other segments.
Basically look for the largest value –
Size of block – size of job
Whichever, gives the highest value job goes to that block
Example –
- Job 1 (size – 100k)
- Block 1 size(50k) – 100k = negative value => Can’t fit
- Block 2 size(200k) – 100k = 100k
- Block 3 size(70k) – 100k =negative value => Can’t fit
- Block 4 size(115k) – 100k = 15k
- Block 5 size(15k) – 100k = negative value => Can’t fit
- Goes to block 2 as 100K is worst case
- Job 2 (size – 10k)
- Block 1 size(50k) – 10k = 40k
- Block 2 already used by job 1. So not possible
- Block 3 size(70k) – 10k = 60k
- Block 4 size(115k) – 10k = 105k
- Block 5 size(15k) – 10k = 5k
- goes to block 4 as 105k is worst case.
- Job 3(size – 35k)
- Block 1 size(50k) – 35k = 15k
- Block 2 already used by job 1. So not possible
- Block 3 size(70k) – 35k = 35k
- Block 4 already used by job 2. So not possible
- Block 5 size(15k) – 35k = negative value => Can’t fit
- goes to block 3 as 35k is worst case.
- Job 4(size -15k)
- Block 1 size(50k) – 15k = 35k
- Block 2 already used by job 1. So not possible
- Block 3 already used by job 3. So not possible
- Block 4 already used by job 2. So not possible
- Block 5 size(15k) – 15k = 0
- Goes to block 1 as 35k is the worst
- Job 5(size – 23k)
- Block 1 already used by job 4. So not possible
- Block 2 already used by job 1. So not possible
- Block 3 already used by job 3. So not possible
- Block 4 already used by job 2. So not possible
- Block 5 size(15k) – 23k = negative value
- Goes no where has to wait indefinitely for other blocks free up.
[table id=370 /]
Next Fit
Next fit is a modified version of ‘first fit’. It begins as first fit to find a free partition but when called next time it starts searching from where it left off, not from the beginning next fit is a very fast searching algorithm and is also comparatively faster than First Fit and Best Fit Memory Management Algorithms
Example –
- Job 1 (size – 100k)
- Can’t fit in block 1 as 50k(block size) <100k(job size)
- Can fit in block 2 as 200K > 100K (Size of block more than size of process)
- 100K remains empty in this block now.
- Job 2 (size 10k)
- Last job entered in block 2 so will start from block 3 now
- Goes to block 3 as block size(70k) > job size(10k)
- Job 3(size 35K)
- Last job entered in block 3 so will start from block 4 now
- Goes to block 4 as block size(115k) > job size(10k)
- Job 4(size 15k)
- Last job entered in block 4 so will start from block 5 now
- Goes to block 5 as block size(10k) = job size(10k)
- Job 5(23k)
- Last job entered in block 5 and there no further blocks, so goes back to block 1
- Goes to block 1 as block size(50k) > job size(23k)
Finally it looks like –
[table id=369 /]
Prime Course Trailer
Related Banners
Get PrepInsta Prime & get Access to all 200+ courses offered by PrepInsta in One Subscription

Get over 200+ course One Subscription
Courses like AI/ML, Cloud Computing, Ethical Hacking, C, C++, Java, Python, DSA (All Languages), Competitive Coding (All Languages), TCS, Infosys, Wipro, Amazon, DBMS, SQL and others


Login/Signup to comment