
Types of Trees in Data Structure

Introduction to Types of Trees in Data Structure
In data structures, a tree is a hierarchical and non-linear data structure used for organizing and storing data in a way that resembles an upside-down tree, with a single root node at the top and branches (edges) connecting to various nodes below it.
In data structures, various tree types exist, including binary trees, AVL trees, B-trees, and more, each tailored to specific applications. Each node in a tree structure can have zero or more child nodes, except for the root node, which has no parent.
Introduction to Tree in Data Structure
In data structures, a tree is like a family tree or a hierarchy. It’s a way to organize information where there’s a “parent” at the top (the root), and it can have “children” below it. Each child can also have its own children, and so on.
- Think of it like folders on a computer. You have a main folder (the root), and inside it, you can have subfolders (children). Those subfolders can have more subfolders (grandchildren), and the pattern continues.
Key characteristics of a binary tree include:
Root Node: The topmost node in the tree, serving as the starting point for traversal.
Node: Each node in the tree holds a value or data element.
Left Child: A child node positioned to the left of its parent node.
Right Child: A child node positioned to the right of its parent node.
Parent Node: A node that has one or more child nodes.
Leaf Node: A node with no children.
Types of Trees in Data Structure
Binary Tree:
A binary tree is a tree data structure in which each node has at most two children, referred to as the left child and the right child.
Binary Tree Traversal:
Binary trees can be traversed in different ways to access their nodes. The three most common traversal methods are:
In-Order Traversal: In this traversal, nodes are visited in the order left, root, right. It is commonly used for binary search trees and provides nodes in ascending order when applied to a BST.
Pre-Order Traversal: In pre-order traversal, nodes are visited in the order root, left, right. It is often used for creating a copy of the tree or for certain types of expression evaluation.
Post-Order Traversal: Post-order traversal visits nodes in the order left, right, root. It is used for tasks like deleting nodes from a tree.
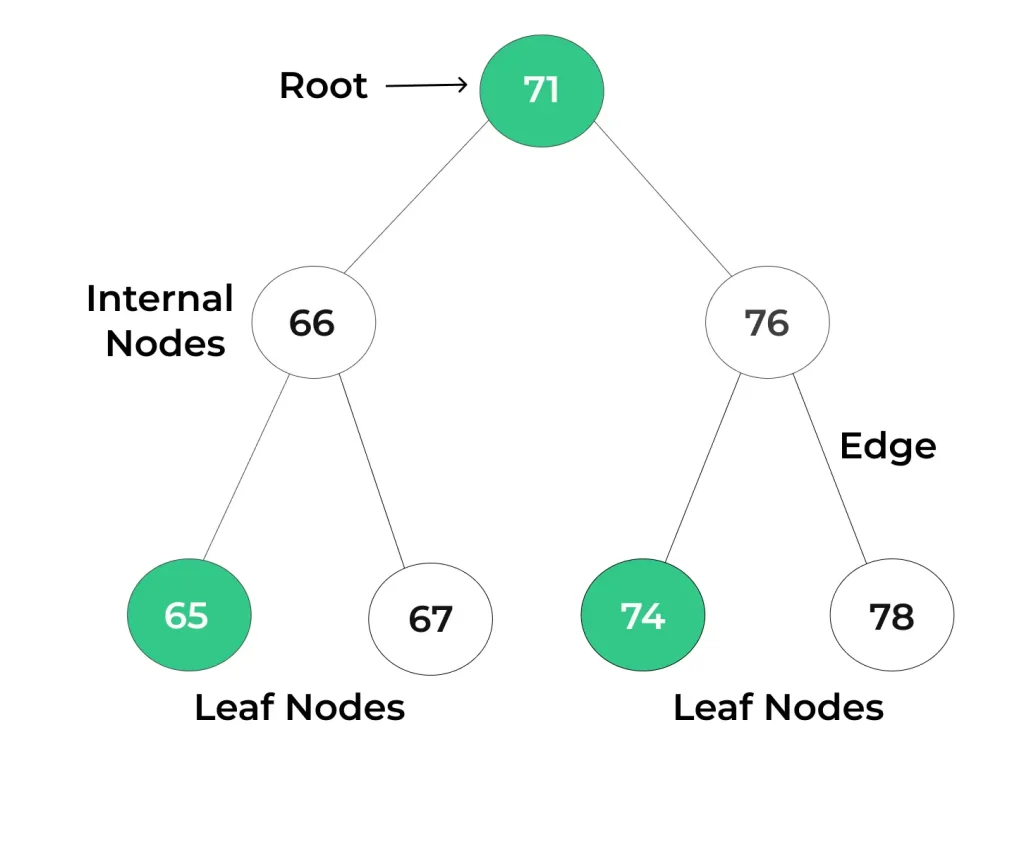
Structure of Binary Tree
Binary Search Tree (BST):
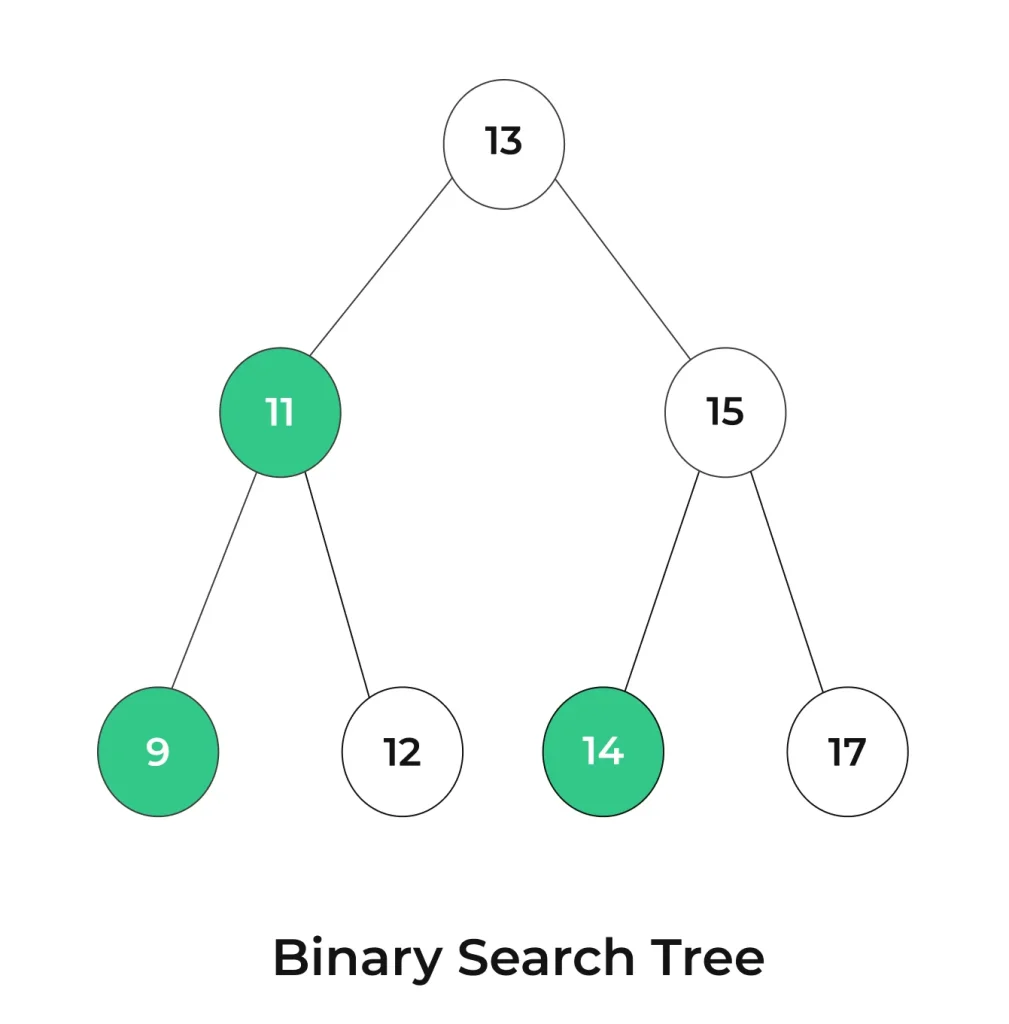
A binary search tree is a binary tree in which the left child of a node contains values less than or equal to the node’s value, and the right child contains values greater than the node’s value.
In a BST, the values in the tree are organized such that for any given node:
- All values in its left subtree are less than or equal to the node’s value.
- All values in its right subtree are greater than the node’s value.
- This ordering property ensures that elements in the tree are sorted in a way that makes searching and other operations efficient.
Structure of Binary Search Tree
AVL Tree:
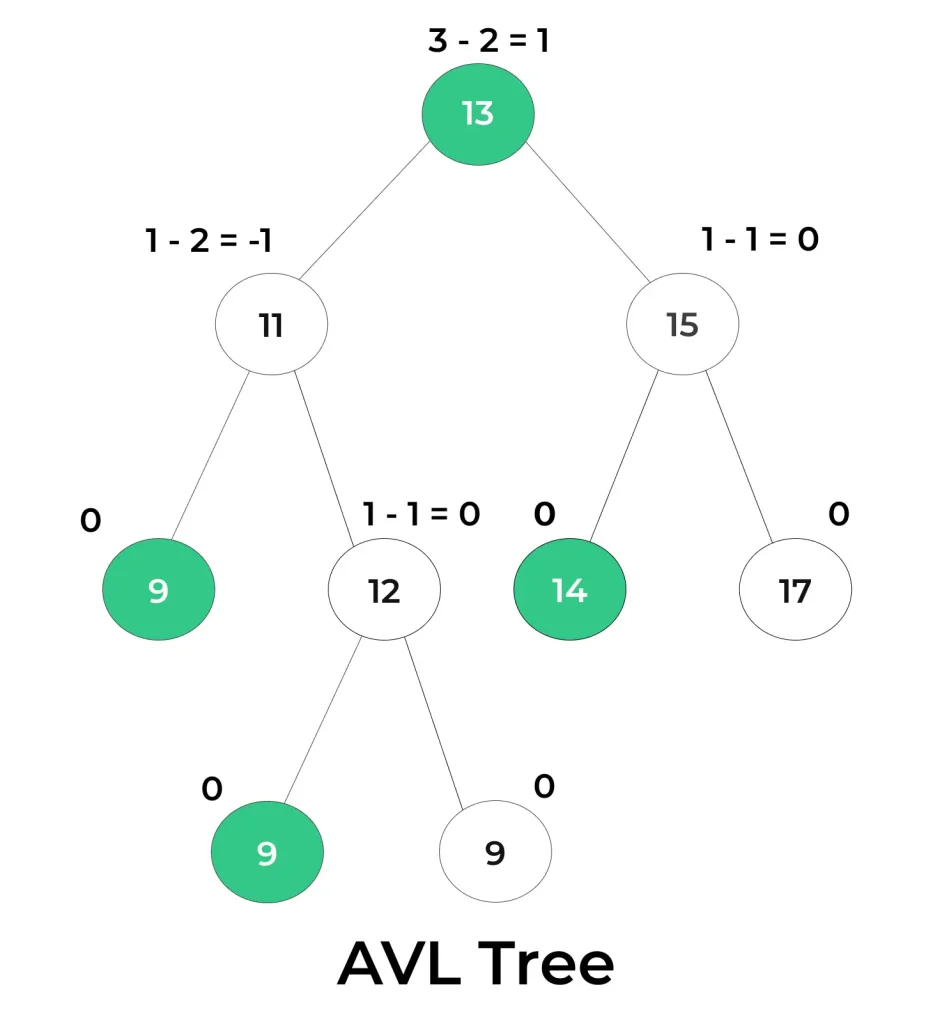
An AVL tree (Adelson-Velsky and Landis tree) is a self-balancing binary search tree where the height of the left and right subtrees of any node differs by at most one.
Two most important points in AVL Tree:
- Balancing Factor: Each node in an AVL tree stores a balance factor, which is the difference between the height of its left and right subtrees. If the balance factor of any node exceeds +1 or -1, the tree is considered unbalanced.
- Balancing Operations: When an insertion or deletion operation potentially disturbs the balance of the tree, AVL trees perform rotation operations to restore balance. There are four types of rotations:
⬅️Left Rotation (LL Rotation)
➡️Right Rotation (RR Rotation)
⬅️➡️Left-Right Rotation (LR Rotation)
➡️⬅️Right-Left Rotation (RL Rotation)
These rotations maintain the AVL tree’s balance property.
Structure of AVL Tree

Red-Black Tree:
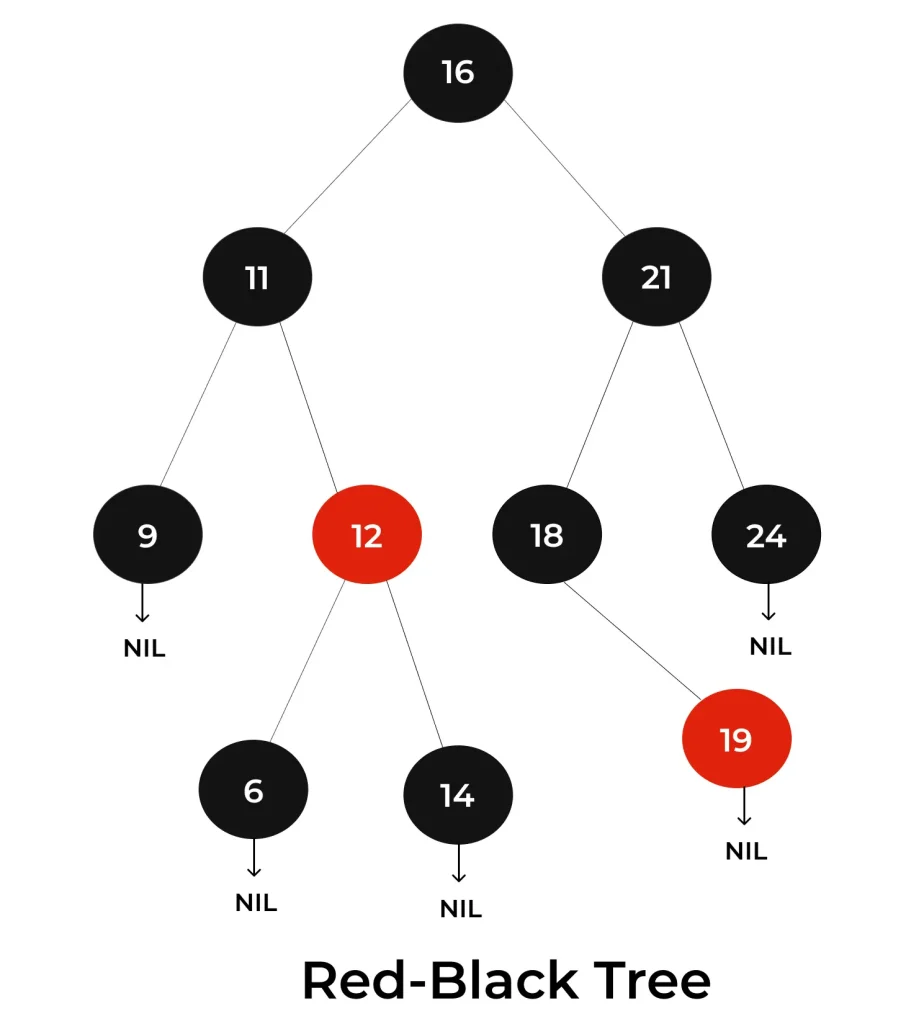
A red-black tree is a self-balancing binary search tree with additional properties where each node is colored either red or black, and specific rules ensure the tree’s balance.
Two foremost important points about Red-Black Tree :
- Balancing Criteria: Red-black trees maintain balance using color-coded nodes (either red or black) and the following criteria:
- Every node is colored either red or black.
- The root node is always black.
- Red nodes cannot have red children; in other words, no two adjacent (parent and child) red nodes are allowed.
- Every path from the root to a null (leaf) node must have the same number of black nodes. This property ensures that the tree remains balanced.
- Balancing Operations: Red-black trees employ a set of rotations and color flips to restore balance after insertions and deletions. These operations ensure that the tree remains approximately balanced and that the longest path from the root to any leaf node (the height) is at most approximately twice as long as the shortest path.
Structure of Red-Black Tree
B-Tree:
A B-tree is a self-balancing tree structure that can have a variable number of child nodes per node, making it suitable for organizing large amounts of data on disk or in databases.
Applications:
B-trees are widely used in various applications, including:
- File systems: B-trees are used to organize directory structures and file metadata efficiently.
- Databases: B-trees are used for indexing data to enable fast retrieval and modification.
- File organization: B-trees can be used for efficient indexing in databases, allowing for rapid searching based on key values.
- External memory algorithms: B-trees are valuable in scenarios where data doesn’t entirely fit in memory and must be read from and written to disk.
Characteristics of Types of Trees in Data Structure
Key characteristics of trees in data structures include:
Root: The topmost node in the tree, which serves as the starting point for accessing all other nodes in the tree. There is only one root node in a tree.
Node: A fundamental unit of a tree data structure, each node contains data (or a value) and may have zero or more child nodes.
Parent and Child: Nodes in a tree are connected by edges (branches), where one node is the parent of another node if it is connected to it directly via an edge. Conversely, the connected node is the child of its parent.
Leaf Node: A node that has no children is called a leaf node. Leaf nodes are the endpoints of a tree’s branches and do not have any child nodes.
Internal Node: Any node in the tree that is not a leaf node is considered an internal node. Internal nodes have one or more child nodes.
Depth: The depth of a node in a tree is the number of edges in the path from the root node to that particular node. The root node has a depth of 0.
Height: The height of a tree is the length of the longest path from the root node to a leaf node. It represents the maximum depth of the tree.
Applications of Tree in Data Structure
Following are the applications of Tree in Data Structure :
To Wrap it up:
From the simplicity of binary trees to the complex balance of AVL trees and red-black trees, and from the storage optimization of B-trees to the specialized use cases of tries and quad/octrees, the versatility of tree structures cannot be overstated. Types of Trees in Data Structure are not merely a theoretical concept; they are the backbone of efficient data organization and manipulation in computer science and software engineering.
Learn DSA
Prime Course Trailer
Related Banners
Get PrepInsta Prime & get Access to all 200+ courses offered by PrepInsta in One Subscription
FAQs
Common examples include binary tree, binary search tree, AVL tree, and B-tree. These structures are used to organize hierarchical data efficiently.
They are used in file systems, databases, and artificial intelligence for organizing data. Choosing the right structure helps improve performance and memory usage.
A binary tree allows a flexible structure, while an AVL tree maintains balance for faster operations. Each has its own advantages based on the use case.
Yes, libraries like anytree and binarytree help developers build and visualize tree structures easily. These tools simplify implementation and testing.
Get over 200+ course One Subscription
Courses like AI/ML, Cloud Computing, Ethical Hacking, C, C++, Java, Python, DSA (All Languages), Competitive Coding (All Languages), TCS, Infosys, Wipro, Amazon, DBMS, SQL and others


Login/Signup to comment