
Disk Scheduling Algorithms in Operating System

Disk Scheduling Algorithms in Operating System
As we all know a hard disk(typically found in a computer) is a collection of disks placed on the top of one another. A typical hard disk may have 100-200 such disks stacked.
Now to have the best seek time or reduce seek time of an hard disk, we have different types of algorithms.
There are more advanced Disk Scheduling Algorithms in Operating System which are trade secrets of companies like – HP, Sandisks, etc. You have to work in those companies ;), to know them.
Before reading further we definitely suggest you please check out this page first as its PreRequisite before Reading – Magnetic Disks Structure
Types of Disk Scheduling Algorithms
First Come First Serve (FCFS)
Now, this algorithm is fairly simple. In the order the request would come, in the same order visit the address on the disk.
Example –
Track Range from 0 to 199 and head initially is rested on 50
95, 180, 34, 119, 11, 123, 62, 64
First the head from 50 goes to 95 then→95→180→34→119→11→123→62→64
Total Head Movement Computation: (THM)
(95 – 50) + (180 – 95) + (180-34) + (119-34) + (119-11) + (123-11) + (123-62) + (64-62)
Trick
Now rather than doing (95 – 50) + (180 – 95) since direction doesnt change we can do (180 – 50).
The above step will save a lot of your time.
= (180 – 50) + (180-34) + (119-34) + (119-11) + (123-11) + (123-62) + (64-62) = 130 + 146 + 85 + 108 + 112 + 61 + 2 (THM) = 644 tracks
Assuming a seek rate of 5 milliseconds is given, we compute for the seek time using the formula:
Seek Time = THM * Seek rate = 644 * 5 ms
Seek Time = 3,220 ms

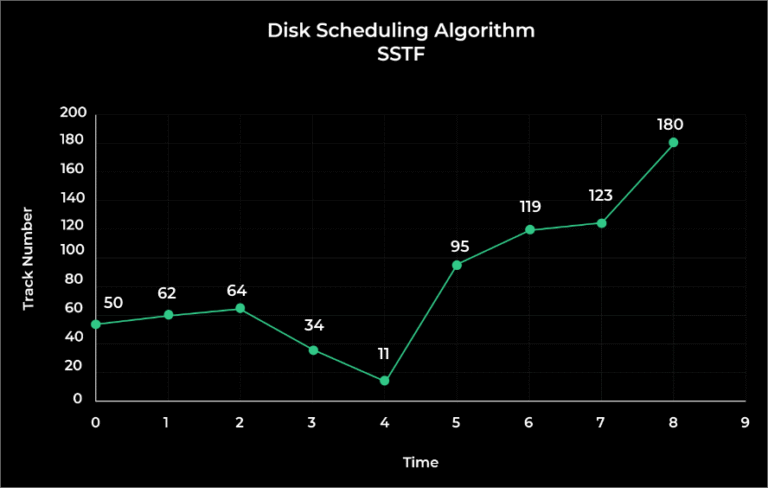
Shortest Seek Time First (SSTF)
Now, even in SSTF to and fro movement is there a lot. Wouldn’t it be better if we just moved in one direction and once all requests in that direction are complete changed the direction and moved to 2nd direction.
Note – If in the question the initial direction of movement is given then, Follow that, if the direction is not given then, the which ever is the nearest end that direction is chosen.
For example : In this question the Read-write head initially is at 50. The nearest b/w 0 or 199 is 0.
So direction of movement will be that.
Example –
Track Range from 0 to 199 and head initially is rested on 50
95, 180, 34, 119, 11, 123, 62, 64
(THM) = (50 – 0) + (180 – 0) = 230
Seek Time = THM * Seek rate = 230 * 5ms
Seek Time = 1150 ms

Elevator (SCAN)
Now, even in SSTF to and fro movement is there a lot. Wouldn’t it be better if we just moved in one direction and once all requests in that direction are complete changed the direction and moved to 2nd direction.
Note – If in the question the initial direction of movement is given then, Follow that, if the direction is not given then, the which ever is the nearest end that direction is chosen.
For example : In this question the Read-write head initially is at 50. The nearest b/w 0 or 199 is 0.
So direction of movement will be that.
Example –
Track Range from 0 to 199 and head initially is rested on 50
95, 180, 34, 119, 11, 123, 62, 64
(THM) = (50 – 0) + (180 – 0) = 230
Seek Time = THM * Seek rate = 230 * 5ms
Seek Time = 1150 ms

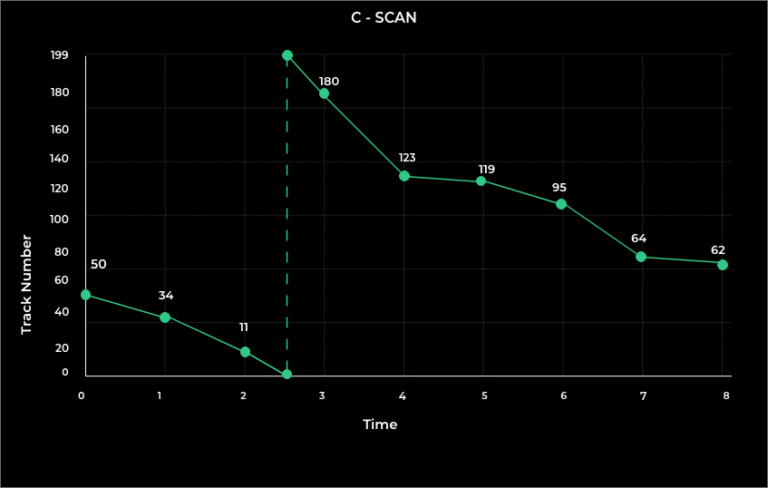
Circular SCAN (C- SCAN)
The idea comes from a disk, this is a modified version of scan, in which we changed the direction once we reached the end address for that scan.
Like in previous example, once we reached 0 we changed the direction.
Wouldn’t it be a little better if we could start from 199 instead and start servicing in that direction?
This algorithm improves the unfair situation of the end tracks against the middle tracks. Using the same sets of example in FCFS the solution are as follows:
Its an improvement over elevator
Note – In CSCAN a new variable alpha(α) is there which is basically adjustment time to shift from end to start(in this case from 199 to 0).
In ideal cases alpha(α) is 0. But, in real time cases alpha is some mili seconds.
Assume α = 20ms
(THM) = (50 – 0) + (199 – 62) + α = 50 + 137 + 20 (THM) = 207 tracks
Seek Time = THM * Seek rate = 207 * 5ms
Seek Time = 1035 ms
LOOK
Look is exactly like SCAN, but rather than going end to end like going to 0 and 199 both depending on the direction of the movement.
It looks for the last service required in either direction, hence called look.
In our case 11 and 180 are the last services.
(THM) = (50-11) + (180-11) = 39 + 169 = 208
(THM) = 208 tracks
Seek Time = THM * Seek rate = 208 * 5ms
Seek Time = 1040 ms

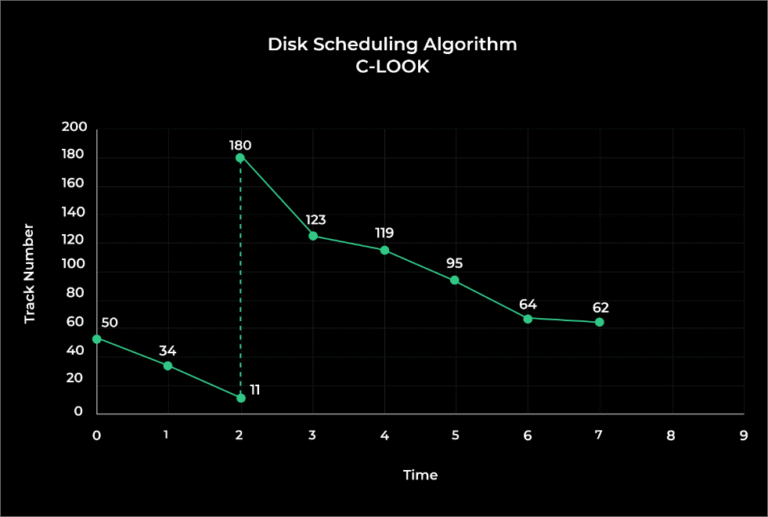
C – LOOK
C look again is modified version of looks. It is knows the last services in the either direction and also has alpha value(α) as, shift adjustment value.
Take alpha value as 20ms again.
(THM) = (50-11) + (180-62) + α = 39 + 118 + 20 (THM) = 177 tracks
Seek Time = THM * Seek rate = 177 * 5ms
Seek Time = 885 ms
1) SSTF is better than FCFS always.
2) Scan in most cases or in average cases is better than SSTF and FCFS
Most operating Systems work on a advanced(can't tell even we don't know, they are trade secrets of big companies) version of SCAN and CLOOK.
Prime Course Trailer
Related Banners
Get PrepInsta Prime & get Access to all 200+ courses offered by PrepInsta in One Subscription

Get over 200+ course One Subscription
Courses like AI/ML, Cloud Computing, Ethical Hacking, C, C++, Java, Python, DSA (All Languages), Competitive Coding (All Languages), TCS, Infosys, Wipro, Amazon, DBMS, SQL and others


Login/Signup to comment