
Indexing and it’s Types

Indexing
In this article, we will learn about Indexing and its types. Indexing is the process of organizing and structuring data to enable efficient search and retrieval. It involves creating an index, which acts as a roadmap or guide to the data. We will explore the various types of indexing and delve into their importance in organizing and accessing data effectively.
Indexing and it’s Types
- An index
- Takes a search key as input.
- Efficiently returns a collection of matching records.
- An Index is a compact table with two columns.
- The first column stores a duplicate of the primary or candidate key from table.
- The second column contains pointer that hold the disk block addresses where the corresponding key-value is stored.
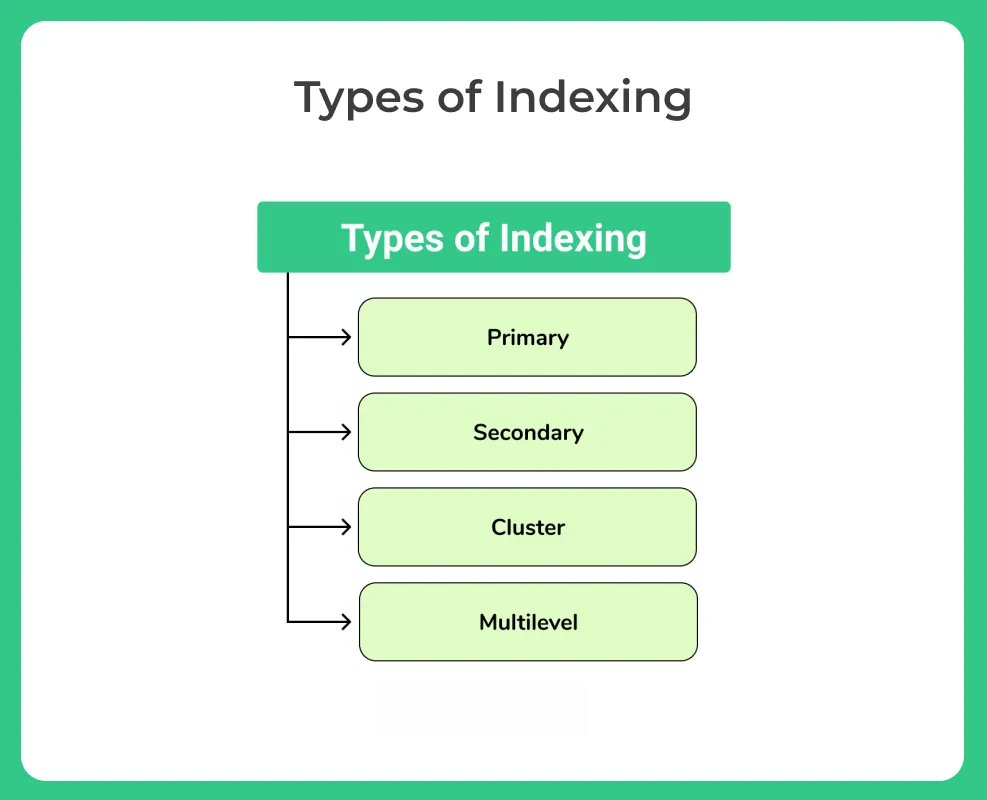
- There exist four primary types of indexing method.
Primary IndexingSecondary IndexingCluster IndexingMultilevel Indexing


Primary Indexing
- Primary indexing helps in efficiently retrieving records based on their primary key values.
- It creates an index structure that maps primary key values to disk block addresses.
- The primary index consists of a sorted list of primary key values and their corresponding disk block pointers.
- It speeds up data retrieval by minimizing search efforts and is particularly useful for primary key-based queries.
- Primary Indexing is further divided into two types.
- Dense Index
- Sparse Index
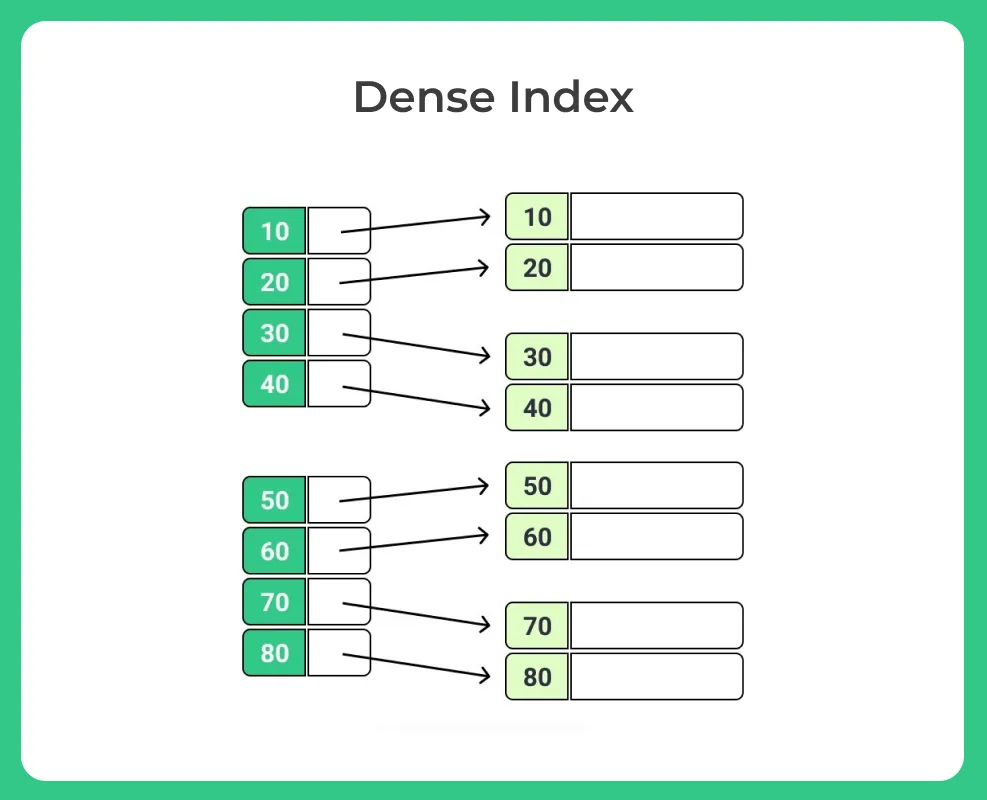
Dense Index
- A Dense Primary Index is a type of primary index in a database management system (DBMS).
- It contains an index entry for every record in the table, resulting in a one-to-one mapping between the index and the table.
- Dense Primary Indexes are particularly useful in scenarios where random access to individual records is frequent or essential.
- Enables direct access to any record by using the primary key.
- As every record requires an index entry, the Dense Primary Index can consume significant storage resources, especially for large tables.
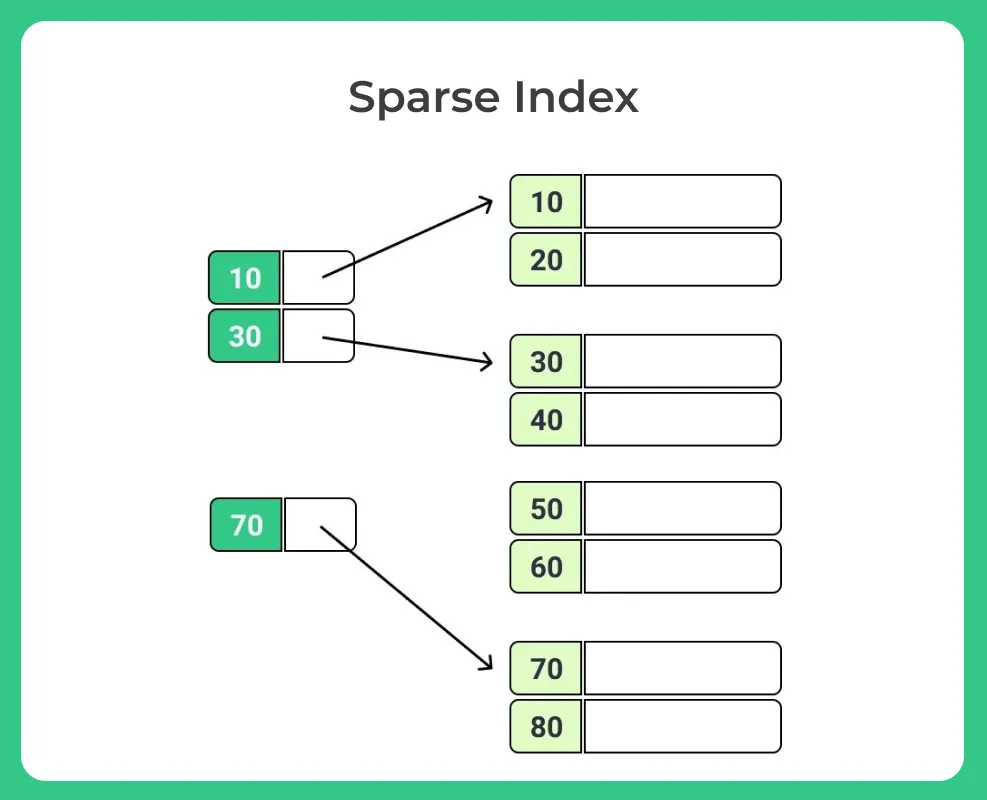
Sparse Index
- A Sparse Primary Index is a type of primary index in a database management system (DBMS).
- Unlike a Dense Primary Index, it contains index entries for only a subset of records in the table, rather than every record.
- It also improves the efficiency of index maintenance operations, such as inserts, updates, and deletes, as fewer index entries need to be modified.
- This allows for efficient access to specific records based on their primary key values, as the index provides a direct path to the relevant data.
- However, it’s important to note that the efficiency of using a Sparse Primary Index depends on the selectivity of the index, meaning the ratio of the number of indexed records to the total number of records in the table.
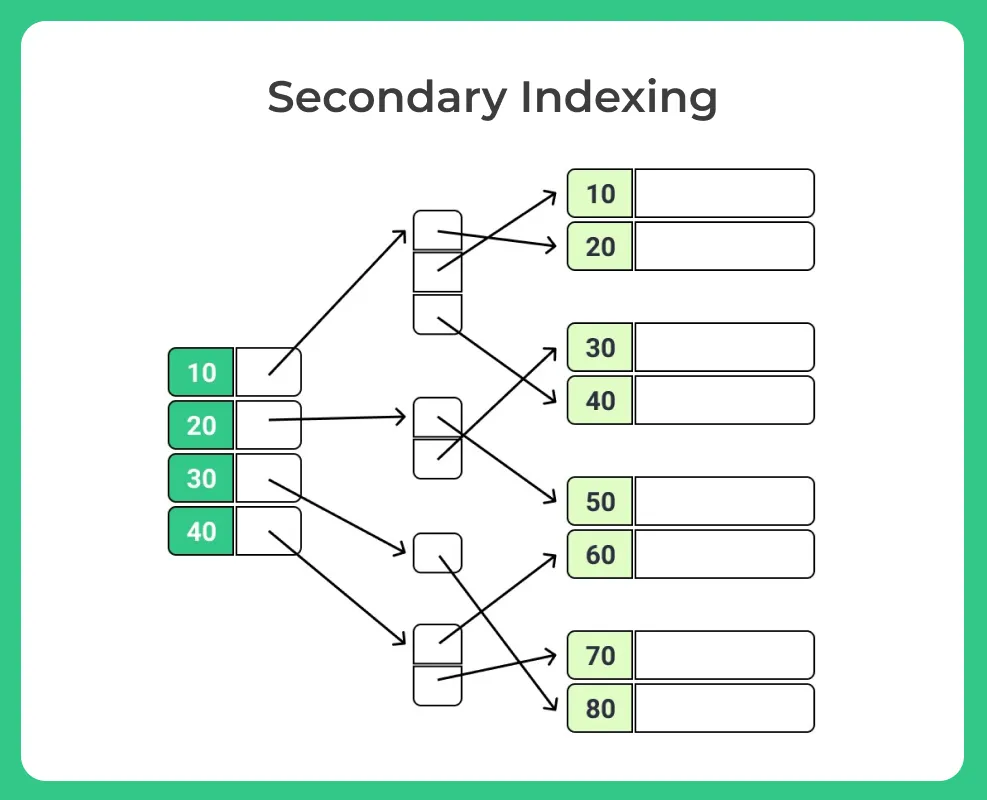
Secondary Indexing
- Secondary indexing is used to improve the search performance of frequently queried non-key attributes/columns in a database table.
- Unlike primary indexing, which is based on the primary key, secondary indexing focuses on non-key columns.
- It creates an index structure that maps the values of the indexed column to the corresponding disk block addresses or pointers where the records are stored.
- Secondary indexes enable faster access to records based on the values in the indexed column, reducing the need for full table scans.
Example
- Creation of Secondary Index: A secondary index is created on the “Location” column of the customer database table.
- Index Structure: The secondary index structure maps distinct “Location” values to their corresponding disk block addresses or pointers.
- Efficient Location-based Queries: With the secondary index, queries that involve searching for customers based on a specific location can be executed more efficiently.
Cluster Indexing
- Cluster indexing is a method of indexing used in database management systems (DBMS) to physically order records in a table based on the indexed columns.
- The indexed column(s) in a cluster index determine the physical order of the records in the table.
- Cluster indexing is particularly useful for range queries and sequential access patterns.
- Cluster indexing can be applied to both primary and secondary indexes, depending on the DBMS capabilities and requirements.
Example
- Let’s consider a database table called “Employees” with columns like “EmployeeID,” “Name,” “Department,” and “Salary.”
- We decide to create a cluster index on the “Department” column.
- The cluster index organizes the data physically on disk based on the “Department” values.
- Rows with the same “Department” value are stored together in the same or nearby data pages.
- For example, all employees from the “Sales” department will be stored together, followed by the “Marketing” department, and so on.
- When a query is executed that involves filtering or sorting based on the “Department” column, the database can quickly locate the relevant data pages.
- This improves query performance, as the database doesn’t need to scan the entire table but can directly access the clustered data pages.
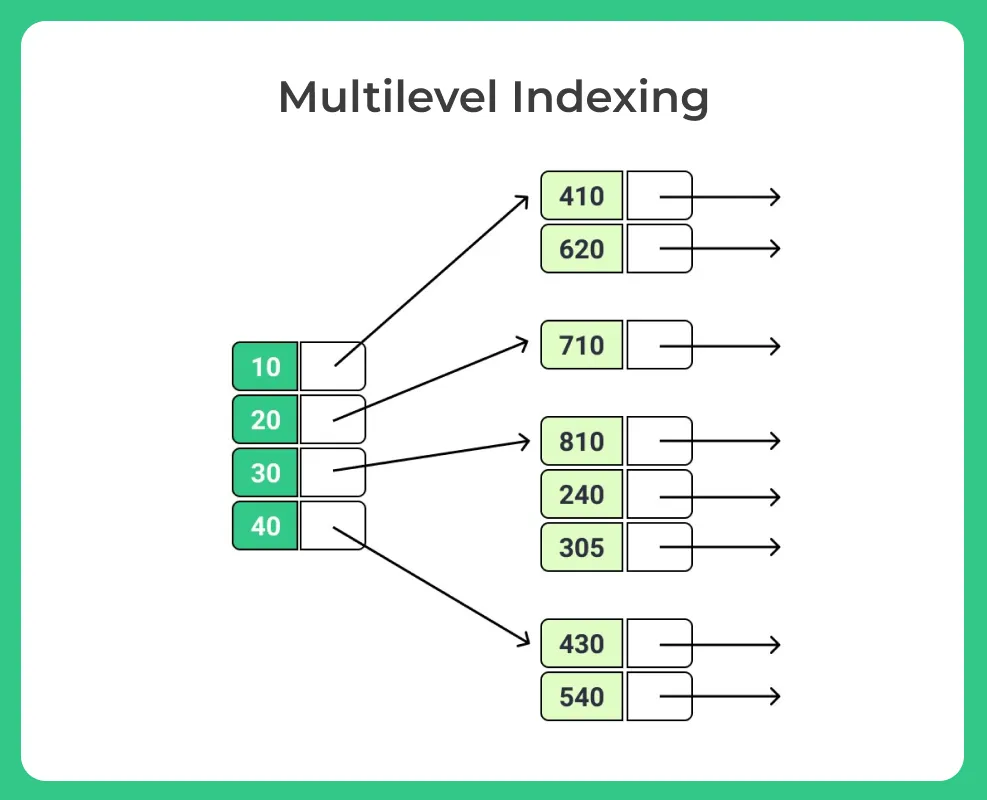
Multilevel Indexing
- Multilevel indexing is a technique used in database systems to efficiently index large amounts of data.
- It involves creating multiple levels of indexes to navigate and access the data.
- The first level index, also known as the primary index, provides an entry for each block or page of data.
- The primary index is usually based on the primary key of the table.
- Each entry in the primary index points to a block or page containing a secondary index.
- The secondary index is created on a secondary key or non-key attribute of the table.
- The secondary index provides a way to locate specific records within a block or page.
B-Tree Indexing
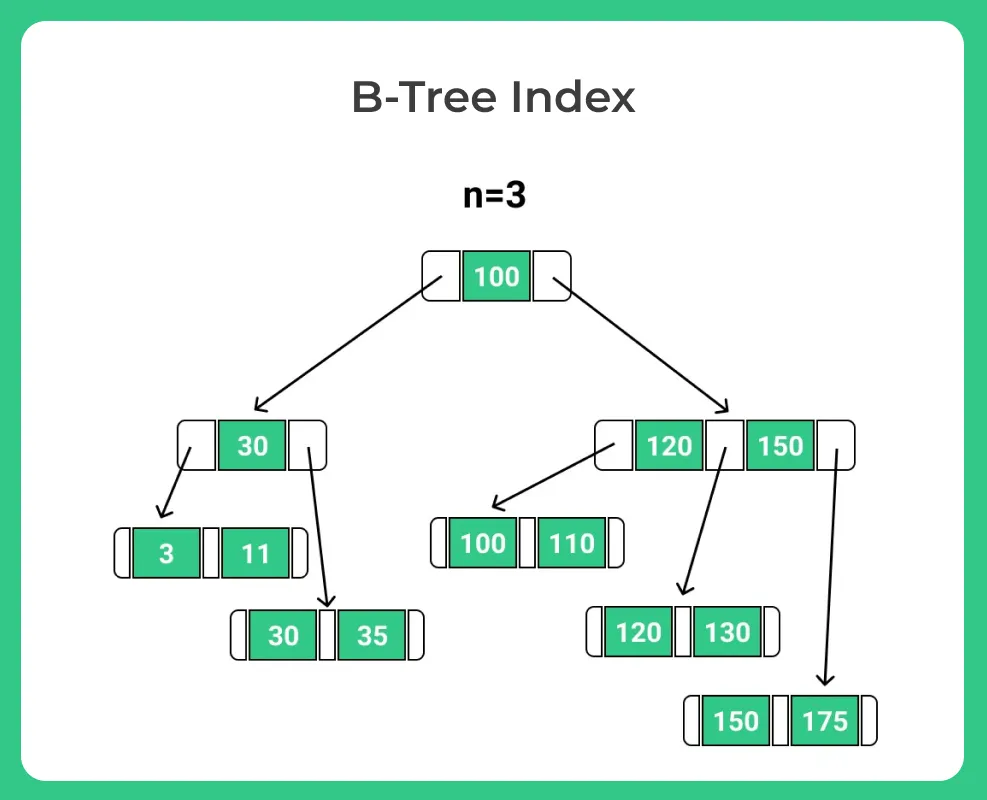
- B-tree indexing is a widely used indexing technique in database systems for efficient data storage and retrieval.
- It is specifically designed for disk-based storage systems, where data is stored on hard drives or solid-state drives (SSDs).
- A B-tree is a balanced tree data structure that allows for efficient search, insertion, and deletion operations.
- It is called a “B-tree” because it is a balanced version of a binary tree.
- The B-tree consists of nodes, where each node contains multiple keys and pointers to child nodes.
Properties of B-Tree
- In a B-tree, the paths from the root to the leaves tend to have approximately equal lengths.
- For any node in a B-tree that is neither the root nor a leaf, the number of its children falls within the range of n/2 to n, where n represents the degree of the B-tree.
Advantages of Indexing
- Improved Query Performance: Indexing allows for faster data retrieval by providing a quick and efficient way to locate specific data records. Queries that involve indexed columns can benefit from reduced search time and improved query performance.
- Efficient Data Filtering: Indexes enable efficient data filtering by narrowing down the search space. By using index-based conditions in queries, the database engine can quickly identify the relevant data, resulting in faster response times.
- Accelerated Sorting and Ordering: Indexes facilitate speedy sorting and ordering of query results. When a query requires sorting based on an indexed column, the database can leverage the index structure to retrieve the data in the desired order more rapidly.
- Enhanced Concurrency: Indexing can improve concurrency in database systems. With indexes, multiple users can simultaneously access and modify the data without causing significant contention, as the indexed data is organized and accessed efficiently.
- Increased Data Integrity: Indexes can enforce data integrity constraints, such as primary key or unique key constraints. They help ensure that duplicate or inconsistent data entries are prevented or quickly identified.
- Optimal Disk I/O Utilization: By reducing the number of disk reads required to retrieve data, indexes optimize disk I/O utilization. This leads to more efficient usage of storage resources and improved overall system performance.
Disadvantages of Indexing
- Increased Storage Space: Indexes require additional storage space to store the index structure. This can result in increased disk space usage, especially for large databases with multiple indexes. The storage overhead of indexes should be considered when designing a database.
- Overhead on Data Modification: Indexes introduce additional overhead when modifying data. Inserts, updates, and deletes not only affect the data itself but also require updating the corresponding indexes. This can lead to slower data modification operations, especially on heavily indexed tables.
- Index Maintenance Overhead: Indexes require ongoing maintenance to remain accurate and effective. As data is modified, indexes need to be updated accordingly. This maintenance overhead can impact system performance, especially in scenarios with frequent data modifications.
- Increased Complexity and Overhead on Data Loading: When bulk loading or importing large amounts of data into a database, indexes can slow down the process. Each data insertion requires updating the associated indexes, resulting in increased complexity and longer data loading times.
- Index Selection Overhead: The database engine needs to evaluate and choose the appropriate indexes for query execution. In complex database systems with numerous indexes, the overhead of index selection and optimization can impact query performance and system response times.
Prime Course Trailer
Related Banners
Get PrepInsta Prime & get Access to all 200+ courses offered by PrepInsta in One Subscription
Get over 200+ course One Subscription
Courses like AI/ML, Cloud Computing, Ethical Hacking, C, C++, Java, Python, DSA (All Languages), Competitive Coding (All Languages), TCS, Infosys, Wipro, Amazon, DBMS, SQL and others


Login/Signup to comment