
Hashing in DBMS

What is Hashing?
Hashing is an effective technique to calculate the direct location of the data record on the disk using a function key without using a sequential index structure as a result data retrieval time decreases. In this article, we will learn about Hashing in DBMS.
Hashing in DBMS
In this article, we will learn about Hashing in DBMS.
- In a huge database structure, it is difficult to search all index values sequentially and then reach the destination data block to get the desired data
Hashing is an effective technique to calculate the direct location of the data record on the disk using a function key without using a sequential index structure as a result data retrieval time decreases.- Bucket: Hash file stores data in bucket format, a bucket is nothing but a unit of storage. Typically 1 complete disc block which in turn can store one or more records
- Hash Function: a Hash Function returns a value which is nothing but the address of the desired data block


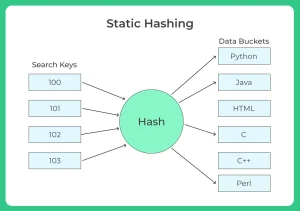
Static hashing
- In static hashing, a search key value is provided by the designed Hash Function always computes the same address
- For example, if mod (4) hash function is used, then it shall generate only 5 values.
- The number of buckets provided remains unchanged at all times
- Bucket address = h (K): the address of the desired data item which is used for insertion updating and deletion operations
Collision and its resolution
- Collision is a condition when there is a fight between multiple data items for the same address
- Simply collision arises when a hash function generates an address at which data is already stored
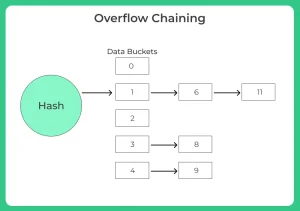
Overflow chaining (closed hashing)
- When buckets are full a new bucket is allocated for the same hash result which is then linked after the previous one
- For example, if h (k) =3 and if some data is already present in this location, now a new bucket is linked to the existing location 3
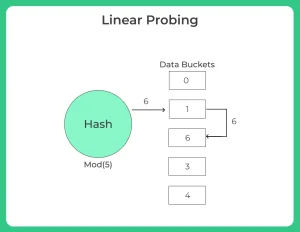
Linear probing (open hashing)
- Hash Function is generating a key at which data is already stored then the next free available bucket is allocated
- For example, if h (k) =6 and is already occupied now check next possible available bucket that is free
Dynamic hashing (extensible hashing)
- The drawback of static hashing is that it does not expand or shrink its size based on the requirement of the database
- Dynamic hashing provides a mechanism in which data buckets are added and removed dynamically and on-demand
- Generally, Hash Function in dynamic hashing is designed to produce a large number of values such that only a few of them are used at initial stages
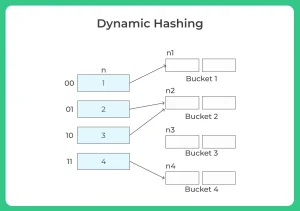
Organization
- The prefix of an entire hash value is taken as a hash index.
- Only a portion of the hash value is used for computing bucket addresses.
- Every hash index has a depth value to represent how many bits are used for computing a hash function.
- These bits can address 2n buckets.
- When all these bits are consumed i.e, when all the buckets are full then the depth value is increased linearly and twice the buckets are allocated.
Conclusion
- Hashing is not advantages when data is organized in some ordering and queries require a range of data.
- Hashing does best when the data is discrete and random
- Hashing algorithms are having high complexity than indexing
- All the hash operations are done at a constant time
Prime Course Trailer
Related Banners
Get PrepInsta Prime & get Access to all 200+ courses offered by PrepInsta in One Subscription
Get over 200+ course One Subscription
Courses like AI/ML, Cloud Computing, Ethical Hacking, C, C++, Java, Python, DSA (All Languages), Competitive Coding (All Languages), TCS, Infosys, Wipro, Amazon, DBMS, SQL and others


Login/Signup to comment