
Data Abstraction in C++
What is Data Abstraction in C++?
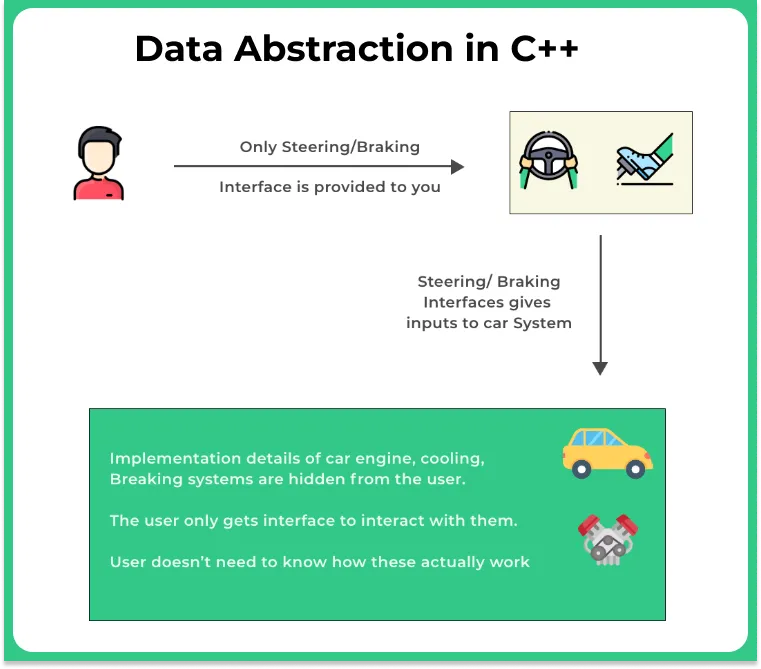
The functionality of hiding the actual details or implementation details for a procedure and just displaying limited essential information or tools, or in other words providing only essential information to the outside world and hiding all the background details and implementation of the procedure is known as Data Abstraction in C++.

Example of Abstraction –
- When you’re taking a ride in a car you only need to know that pressing on the accelerator increases the speed of the car, or pressing on the breaks slows down the car.
- But, you don’t need to know the inside details of the machinery or engine details to know how all of this happens. It is taken care of by the Car manufacturer itself. They just provide you with the interface to drive the car.
Encapsulation is, however, different it is wrapping up and binging all the related data together. For a car having all the engine-related components together and breaking or clutching system together.
Types of Abstraction
Now, there are two types of Abstraction –
- Header files
- Classes
Lets have a look at both of them below –


Header Files –
We all use header files, we import #include to use the power function. We directly use the pow() function as pow(2, 3) to get results.
But, the implementation details are hidden from us, we just get the desired output without knowing what happened in the background.
Classes –
In C++, we can define which data members & member function implementation we want to show to the outside world and which ones we want to hide.
This is done using access specifiers and getters/setters.
How do Access Specifiers help in Data Abstraction?
There are three types of access specifiers in C++
- Public
- Private
- Protected
Let’s have a look at the program below. (There is some issue with the program below, that is data abstraction has not been implemented)
Imagine if this was your password, anybody can change, read or alter password
#include <iostream>
using namespace std;
class myClass {
// data members and functions declared public
public:
int x, y;
// constructor to setup initial value at object creation
// we will learn about constructors later
myClass(int val1, int val2){
x = val1;
y = val2;
}
};
int main(){
myClass obj(10, 15);
// we are directly able to access values
obj.x = 100;
obj.y = 200;
cout << "x: " << obj.x << " y: " << obj.y << endl;
return 0;
}Output
x: 100 y: 200
How Data Abstraction solves this?
Data abstraction solves this by –
- Making relevant data members private
- Creating function interfaces designed to do specific things allowed the coder to work with these data members
Let’s see some examples –
- Example 1: Shows how abstraction works using getters and setters
- Example 2: Shows how Data Abstractions works in real-life examples
Example 1 (Data Abstraction)
#include <iostream>
using namespace std;
class myClass {
// data members and functions declared public
private:
int x, y;
public:
void setX(int x1){
x = x1;
}
void setY(int y1){
y = y1;
}
int getX(){
return x;
}
int getY(){
return y;
}
};
int main(){
myClass obj;
// setting values with setter interface
obj.setX(20);
obj.setY(40);
// following will give error as
// we can't access private data members
// x = 100; error
// y = 200; error
// this is how you read with getter interface
cout << "x: " << obj.getX() << " y: " << obj.getY() << endl;
return 0;
}Output
x: 20 y: 40
Example 2 (Data Abstraction)
The following example will really tell you how Data Abstraction really protects your data –
#include <iostream>
using namespace std;
class User {
// data members are private
private:
int userID;
string password;
// member function interface is public
// to allow specific methods to work with data members
public:
void createProfile(int id, string pass){
userID = id;
password = pass;
cout << "User: " << userID << " account created" << endl;
}
// using this we don't give interface to share actual password
// infact the actual password is hidden as private data member
// we just let the user know if he entered the correct password or not
// this is data abstraction
void authenticate(string str){
if(password == str)
cout << "Login Successful";
else
cout << "Incorrect Password";
}
};
int main(){
User user1;
user1.createProfile(1, "pass123456$");
// following will not work as password is private
// user1.password = "1234";
// this will work as function in public
user1.authenticate("pass0000");
return 0;
}Output
User: 1 account created Incorrect Password
Difference between Data Abstraction and Data Encapsulation
90% of the people forget both data abstraction and encapsulation in the interviews as both of them are more or less same. But, infact they are different.
- Data Encapsulation is the process of hiding the data and programs from the outside world and essentially capsuling them together in one entity.
- Data Abstraction is the process of hiding the implementation i.e. what is happening inside a function or program from the outside world. Essentially data abstraction is achieved with the help of data encapsulation or we can say abstraction is the result of encapsulation.
- Private members can only be access within the class and their data and implementation is hidden from the outside world
- Public members can be accessed anywhere in the program.
Prime Course Trailer
Related Banners
Get PrepInsta Prime & get Access to all 200+ courses offered by PrepInsta in One Subscription

Get over 200+ course One Subscription
Courses like AI/ML, Cloud Computing, Ethical Hacking, C, C++, Java, Python, DSA (All Languages), Competitive Coding (All Languages), TCS, Infosys, Wipro, Amazon, DBMS, SQL and others


Login/Signup to comment