
SQL SELECT DISTINCT Statement

Introduction
Structured Query Language (SQL) is a programming language that enables users to manage data stored in relational databases. SQL uses various operators to perform various operations, including data retrieval and manipulation.
One of the most commonly used SQL statements is the SELECT statement. In this article, we’ll explore the SELECT DISTINCT statement and how it can be used to retrieve unique values from a table.
What is the SELECT DISTINCT statement?
The SELECT DISTINCT statement is an SQL query that allows you to retrieve unique values from one or more columns in a table. It filters out duplicates and returns only distinct values. It’s often used when you need to know the unique values in a column or when you’re working with large datasets that may contain redundant information.
How does the SELECT DISTINCT statement work?
When you execute a SELECT DISTINCT statement, the database engine retrieves all the rows from the specified table or tables, and then it eliminates the duplicate values in the specified columns. The remaining rows contain only the distinct values.
Syntax of the SELECT DISTINCT statement
The syntax for the SELECT DISTINCT statement is:
SELECT DISTINCT column1, column2, ... FROM table_name [WHERE condition];
Benefits of using the SELECT DISTINCT statement
The SELECT DISTINCT statement is a powerful tool that provides several benefits to users working with databases. Some of the main benefits of using the SELECT DISTINCT statement are:
Example 1: Retrieving unique values from a single column
Retrieving unique values from a single column is a common task in SQL. It involves selecting only the distinct or unique values from a specified column of a table. This can be useful for various reasons, such as identifying all possible options for a certain attribute or removing duplicates from a dataset.
In this statement, “column_name” is the name of the column you want to retrieve the unique values for, and “table_name” is the name of the table that contains the column.
SELECT DISTINCT country FROM customers;
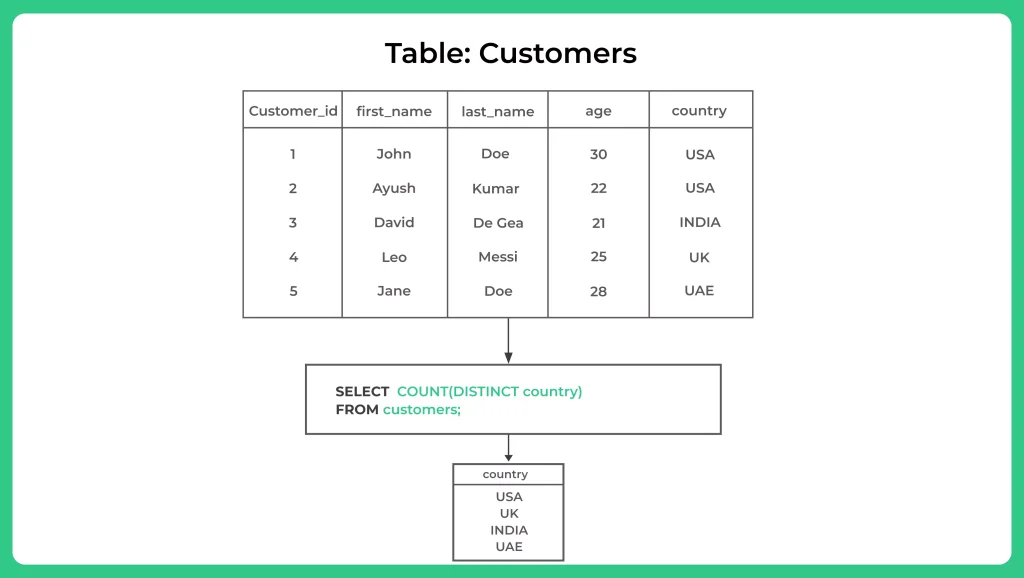
For example, suppose you have a table named “customers” with a column named “country”. To retrieve all unique countries from this column, you can use the following SQL query:
This will return a list of all unique countries from the “country” column of the “customers” table.
Overall, retrieving unique values from a single column is a straightforward task in SQL, and the SELECT DISTINCT statement is a useful tool to accomplish this task.
Example 2: Retrieving unique values from multiple columns
You can also use the SELECT DISTINCT statement to retrieve unique values from multiple columns.
The SQL query you provided is using the SELECT DISTINCT statement to retrieve unique values for the “country” and “first_name” columns from a table called “customers”.
- The “customers” table has several columns, including “customer_id”, “first_name”, “last_name”, “age”, and “country”. Each row in the table represents a single customer, with unique values for each column.
SELECT DISTINCT country,first_name ) FROM Customers
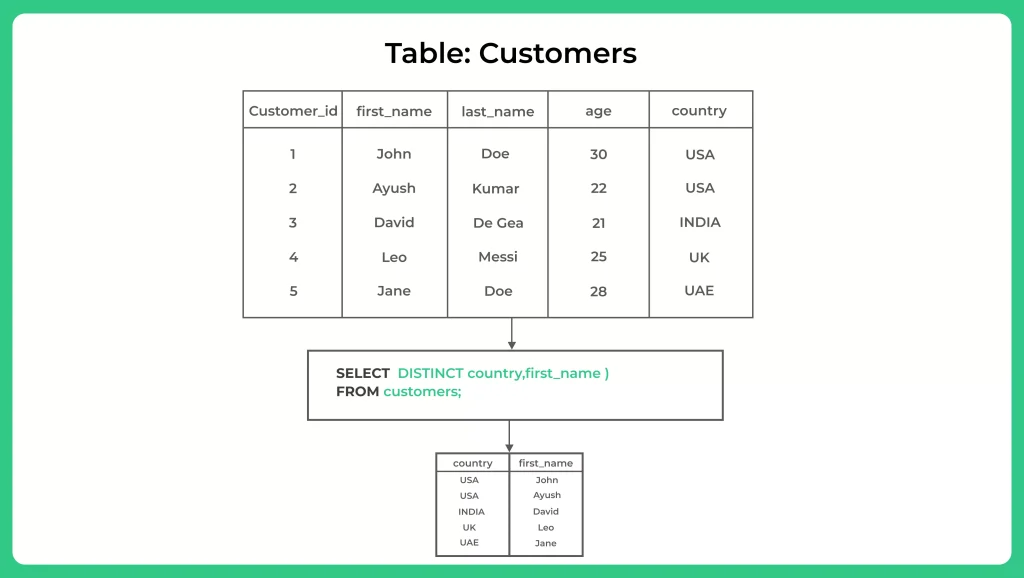
- The SELECT DISTINCT statement is used to retrieve only unique values for the specified columns. In this case, the query will retrieve all unique combinations of “country” and “first_name” from the “customers” table.
- The resulting query output will display a list of all unique combinations of country and first name, with no duplicate values. For example, if there are two customers with the same first name and country, only one of those customers will be included in the query output.


DISTINCT With COUNT
DISTINCT with COUNT is a SQL statement that allows you to count the number of distinct or unique values in a specified column of a table.
The COUNT function is used to count the number of rows that match a particular criterion, such as a specific value or condition. When used in conjunction with the DISTINCT keyword, it allows you to count the number of unique values that meet the criterion.
Example 3: DISTINCT With COUNT
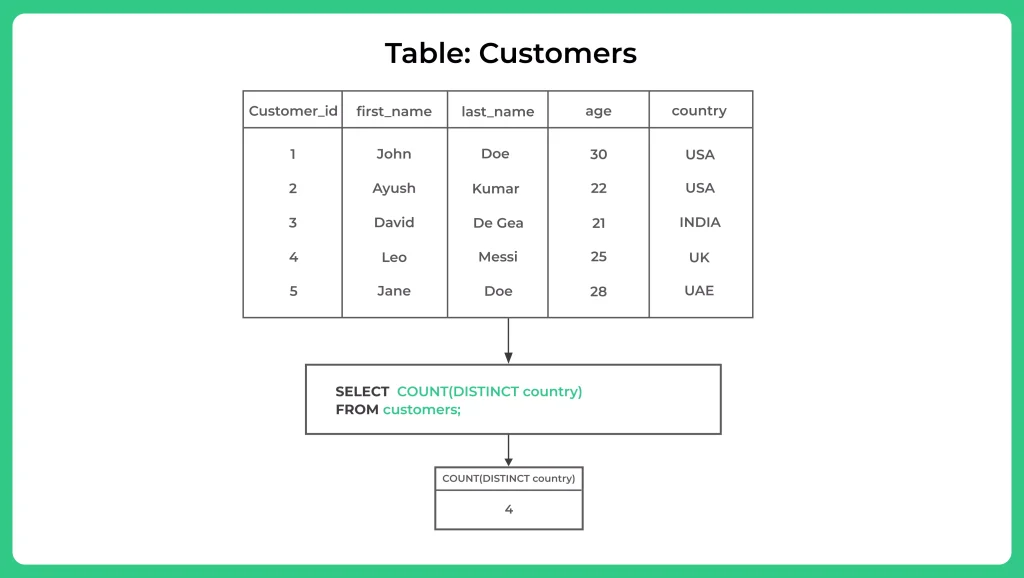
The SQL query you provided is using the COUNT function with the DISTINCT keyword to count the number of unique values in the “country” column of a table called “customers”.
The “customers” table has several columns, including “customer_id”, “first_name”, “last_name”, “age”, and “country”. Each row in the table represents a single customer, with unique values for each column.
SELECT COUNT(DISTINCT country) FROM Customers
Common mistakes when using the SELECT DISTINCT statement
- Mistake 1: Using DISTINCT with too many columns
- Mistake 2: Using DISTINCT with NULL values
- Mistake 3: Using DISTINCT with aggregate functions
Using DISTINCT with too many columns: While it is possible to use the SELECT DISTINCT statement with multiple columns, doing so can significantly slow down query performance and may not provide any additional benefits. It is generally best to limit the use of DISTINCT to the minimum number of columns needed to retrieve unique values.
Using DISTINCT with NULL values: When using the SELECT DISTINCT statement, it is important to be aware that NULL values are treated as distinct values. This means that using DISTINCT with columns that contain NULL values can result in unexpected or inaccurate query results.
Using DISTINCT with aggregate functions: When used with aggregate functions such as COUNT or SUM, the SELECT DISTINCT statement can produce unexpected or inaccurate results. This is because the DISTINCT keyword is applied to the entire result set, rather than individual rows.
Prime Course Trailer
Related Banners
Get PrepInsta Prime & get Access to all 200+ courses offered by PrepInsta in One Subscription

Get over 200+ course One Subscription
Courses like AI/ML, Cloud Computing, Ethical Hacking, C, C++, Java, Python, DSA (All Languages), Competitive Coding (All Languages), TCS, Infosys, Wipro, Amazon, DBMS, SQL and others

