
Dimensionality Reduction Techniques
Dimensionality Reduction Techniques in Machine Learning
for Data Analytics
Dimensionality reduction techniques in machine learning are essential for simplifying high dimensional datasets while preserving meaningful information. In data analytics, large datasets often contain hundreds or thousands of features, which can lead to complexity, overfitting, and increased computation time.
Dimensionality reduction helps address these challenges by reducing the number of input variables, making models faster, more efficient, and easier to interpret.

What is Dimensionality Reduction in Machine Learning?
Dimensionality reduction is the process of reducing the number of features (dimensions) in a dataset while retaining important information.
In simple terms, it transforms complex data into a simpler form without losing its core structure.
Why Dimensionality Reduction is Important in Data Analytics
Using dimensionality reduction techniques in machine learning for data analytics provides several advantages:
- Reduces computational cost
- Improves model performance
- Prevents overfitting
- Removes irrelevant or redundant features
- Enhances data visualization
Types of Dimensionality Reduction Techniques
Dimensionality reduction techniques are broadly divided into:
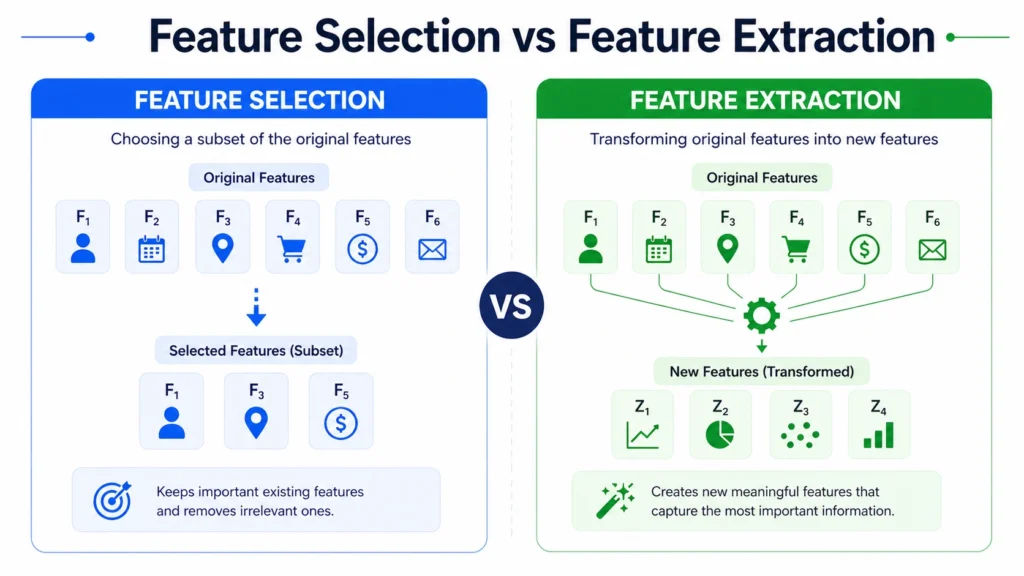
1. Feature Selection Methods: Selecting a subset of original features.
2. Feature Extraction Methods: Transforming data into a lower dimensional space.
1. Feature Selection Techniques:
Feature selection chooses the most relevant features from the dataset.
a. Filter Methods: Based on statistical tests
- Example: Correlation, Chi-square
b. Wrapper Methods: Use machine learning models to select features
- Example: Recursive Feature Elimination (RFE)
c. Embedded Methods: Feature selection during model training
- Example: Lasso Regression
2. Feature Extraction Techniques
Feature extraction creates new features from existing data.
a. Principal Component Analysis (PCA):
- Most popular dimensionality reduction technique
- Converts data into principal components
- Maximizes variance
Widely used in data analytics and visualization.
b. Linear Discriminant Analysis (LDA):
- Used for classification problems
- Maximizes class separability
c. t-Distributed Stochastic Neighbor
- Embedding (t-SNE)
- Used for visualization
- Works well for high-dimensional data
d. Autoencoders:
- Deep learning-based technique
Learns compressed representation of data
Feature Selection vs Feature Extraction
| Feature | Feature Selection | Feature Extraction |
|---|---|---|
| Approach | Select existing features | Create new features |
| Complexity | Low | High |
| Example | RFE | PCA |
| Use Case | Simpler models | Complex datasets |

Practical Implementation (PCA Example in Python)
from sklearn.decomposition import PCA
import numpy as np
# Sample data
X = np.array([[2,3], [3,4], [5,6], [7,8]])
# Apply PCA
pca = PCA(n_components=1)
X_reduced = pca.fit_transform(X)
print("Reduced Data:\n", X_reduced)
Real World Applications of Dimensionality Reduction Techniques
- Image Processing: Reducing pixel dimensions
- Finance: Analyzing large financial datasets
- Healthcare: Reducing medical data complexity
- Marketing Analytics: Customer segmentation with fewer variables
Advantages of Dimensionality Reduction….
- Faster model training
- Better generalization
- Reduced storage requirements
- Improved visualization
Limitations….
- Possible loss of information
- Complex interpretation
- Requires careful method selection
When to Use Dimensionality Reduction
Use when:
- Dataset has too many features
- Model performance is slow
- Data has redundancy or noise
So the final verdict is….
Dimensionality reduction techniques in machine learning play a vital role in simplifying complex datasets and improving model performance.
- By reducing the number of features, these techniques help analysts focus on the most important information while minimizing noise and redundancy.
- Whether using feature selection methods or advanced techniques like PCA and autoencoders, dimensionality reduction is essential for efficient data analytics and machine learning workflows.

Frequently Asked Questions
Answer:
Dimensionality reduction techniques in machine learning are methods used to reduce the number of features while preserving important information.
Answer:
It improves model performance, reduces complexity, and helps visualize high dimensional data.
Answer:
PCA is a technique that reduces dimensionality by transforming data into principal components.
Answer:
Feature selection chooses existing features, while feature extraction creates new ones.
Answer:
There is no single best method, it depends on the dataset and problem.

