
Decision Tree Classifier in Machine Learning
Introduction to Decision Tree Classifier in Machine Learning
Decision Tree Classifier in Machine Learning are a basic yet powerful tool in machine learning. They help make predictions by using a simple, tree-like structure that mirrors how humans make decisions. This guide will explain how Decision Tree Classifiers work, their benefits and drawbacks, and where they are used.
A Decision Tree Classifier is a supervised learning algorithm used for classification tasks. It looks like a flowchart, starting with a root node and branching out into different paths based on conditions. Each path leads to a leaf node, which represents a possible outcome or class label

What is a Decision Tree Classifier?
A Decision Tree Classifier is a supervised learning algorithm used for classification tasks. It operates by recursively splitting the dataset based on feature values, resulting in a tree-like structure where each internal node represents a decision rule, each branch represents an outcome of the rule, and each leaf node represents a class label.
- This hierarchical structure enables the model to classify data points by traversing from the root to a leaf node, following the decisions that correspond to the features of the input data.
Fast Training: They can be trained quickly compared to other algorithms.
Handling Missing Data: They can handle missing data effectively
Structure of a Decision Tree
Understanding the components of a Decision Tree is crucial:
- Root Node: The topmost node that represents the entire dataset and initiates the first split.
- Internal Nodes: Nodes that represent decisions based on feature values, leading to further splits.
- Branches: Connections between nodes that represent the outcome of a decision, guiding the path to the next node.
- Leaf Nodes: Terminal nodes that provide the final classification or decision.
This structure allows the model to systematically break down the data by making a series of decisions based on feature values.

How Does a Decision Tree Classifier in Machine Learning Work?
A decision tree works by splitting the dataset into smaller groups based on certain conditions. It continues splitting until it reaches a decision or classification.
Each split is based on a feature that provides the highest information gain, or in simple terms, gives the best separation between classes.
Components of a Decision Tree
| Component | Description |
|---|---|
| Root Node | The first node (starting point) |
| Decision Node | Internal node where a decision is made |
| Leaf Node | Final output node (no further splitting) |
| Branch | A connection between nodes |
| Splitting | Dividing the dataset based on feature values |

Types of Decision Trees
- Classification Trees: Used when the target variable is categorical (e.g., Yes/No, Pass/Fail).
- Regression Trees: Used when the target variable is continuous (e.g., price, age).
- Binary Trees: Each node splits into two branches only.
- Multi-way Trees: Nodes can have more than two branches.
Key Terminologies You Should Know
- Gini Index: Measures the impurity of a node. Lower value = better split.
- Entropy: Measures randomness or disorder in data.
- Information Gain: How much a feature improves the classification.
- Overfitting: When the model performs well on training data but poorly on unseen data.
- Pruning: Technique to remove unnecessary branches to avoid overfitting.
How to Build a Decision Tree?
Step-by-step process:
- Select the Best Feature: Choose the feature that splits the data best (based on Gini or Entropy).
- Split the Data: Divide the dataset into subsets.
- Repeat: Do this for each subset.
- Stop Splitting: When stopping criteria are met (like max depth, minimum samples, or pure class).
- Prune the Tree: Remove unnecessary splits to improve performance.
Example of a Decision Tree Classifier in Machine Learning (Student Example)
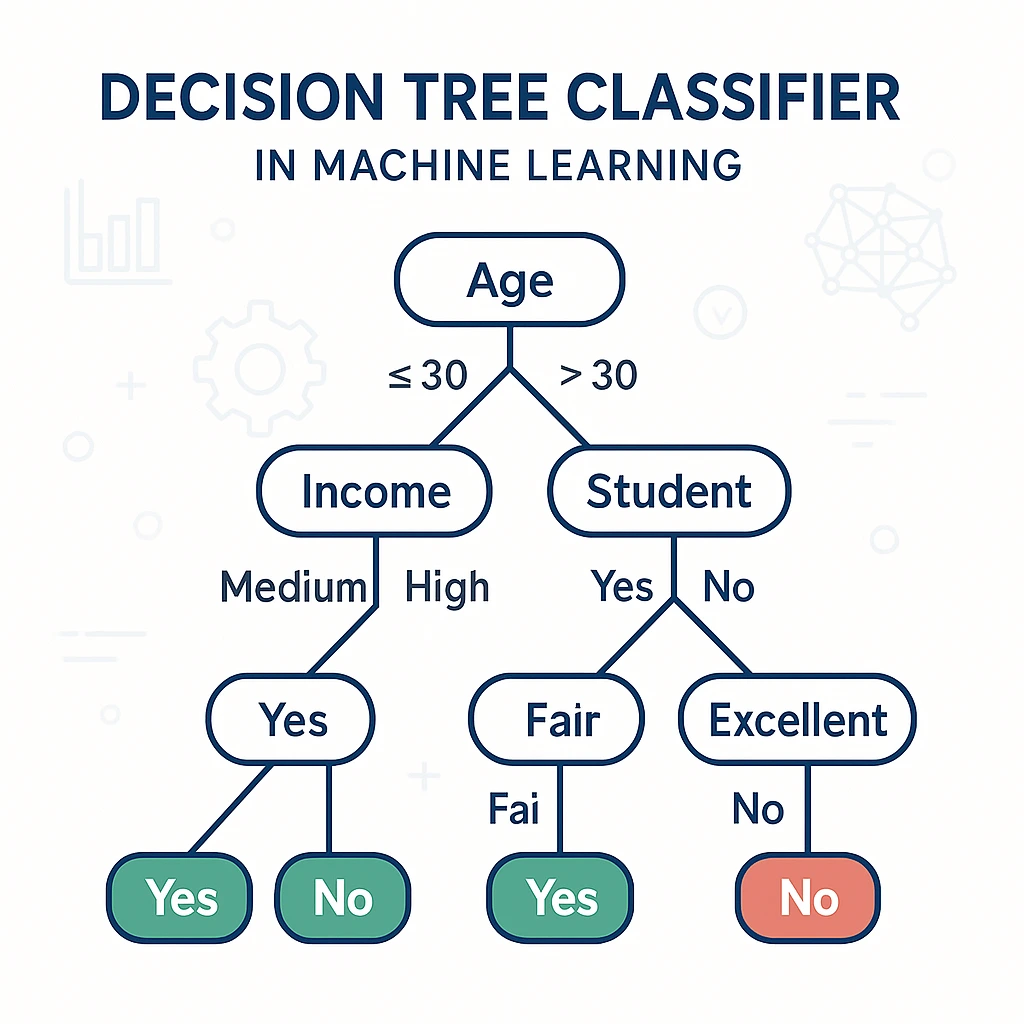
Advantages of Decision Trees
- Easy to understand and visualize
- Works on both categorical and numerical data
- No need for data scaling
- Handles missing values well
- Useful for feature selection
Disadvantages of Decision Trees
- Overfitting: Can learn too much from training data
- Unstable: Small changes in data can change the structure
- Biased Splits: Can be biased with features having more levels
- Complex Trees: May become hard to interpret if too deep
Decision Tree vs Other Algorithms
| Feature | Decision Tree | Logistic Regression | Random Forest |
|---|---|---|---|
| Interpretability | High | Medium | Low |
| Handles Non-Linearity | Yes | No | Yes |
| Overfitting Risk | High | Low | Low |
| Use Case | Simple classification | Binary classification | Binary classification |
Decision Tree in Python (Simple Code Example)
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# Load dataset
iris = load_iris()
X = iris.data
y = iris.target
# Split data
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)
# Train model
clf = DecisionTreeClassifier()
clf.fit(X_train, y_train)
# Predict and evaluate
y_pred = clf.predict(X_test)
print("Accuracy:", accuracy_score(y_test, y_pred)) To Wrap it Up
The Decision Tree Classifier is a powerful and easy-to-understand algorithm that mimics how humans make decisions. It is widely used across industries for solving classification problems. Although it has its challenges, when used properly – with pruning, cross-validation, or as part of an ensemble – it becomes a strong and trustworthy model.
If you’re just starting out in machine learning, mastering decision trees is a great first step. It not only helps you build your understanding of classification problems but also sets the foundation for more advanced topics like Random Forest and Gradient Boosting.
Frequently Asked Questions
Answer:
A Decision Tree Classifier is a supervised learning algorithm used to categorize data by splitting it into branches based on conditions. It works like a flowchart, where each node represents a decision and each branch leads to an outcome.
Answer:
It divides the dataset into smaller subsets based on feature values. The model selects the best feature at each step to split the data, aiming to improve prediction accuracy until it reaches a final decision.
Answer:
It is easy to understand, requires less data preparation, and can handle both numerical and categorical data. It also provides clear decision-making rules, making it beginner-friendly.
Answer:
It is widely used in areas like customer segmentation, fraud detection, medical diagnosis, and recommendation systems where clear decision rules are important.
Answer:
Start by learning basic statistics and data handling skills. Then focus on tools like spreadsheets, databases, and programming languages. Practice with real datasets and build projects to showcase your skills.
Answer:
You need skills in data cleaning, visualization, problem-solving, and basic programming. Understanding data trends and communicating insights clearly is also important.
Answer:
Yes, many beginners transition into data analytics by learning step by step. With consistent practice and the right learning path, even non-technical learners can build strong analytical skills.
Answer:
It is a structured learning program that teaches data analysis skills through online lessons. After completing the course, you receive a certificate that validates your knowledge.
Answer:
Yes, they can be valuable if they include practical projects and real-world scenarios. They help you build skills and improve your chances of getting job opportunities.
Answer:
The duration depends on the course, but most can be completed within a few weeks to a few months, depending on your learning pace and schedule.

