
Classification Analysis in Machine Learning
Classification Analysis in Machine Learning
Classification analysis in machine learning is a comprehensive process of analyzing data to categorize it into predefined classes using statistical methods, data understanding, and predictive modeling. While many people confuse it with classification algorithms, classification analysis is broader, it includes data preparation, feature selection, model building, evaluation, and interpretation.

What is Classification Analysis in Machine Learning?
Classification analysis is the end to end analytical process used to assign data into categories based on learned patterns.
It includes:
- Understanding the dataset
- Preparing and preprocessing data
- Selecting relevant features
- Applying classification algorithms
- Evaluating model performance
- Interpreting results
Classification algorithm = One step inside that workflow
Classification Analysis vs Classification Algorithm
| Aspect | Classification Analysis | Classification Algorithm |
|---|---|---|
| Definition | Complete analytical process | Specific model/technique |
| Scope | Broad (end-to-end) | Narrow (model only) |
| Includes | Data prep, training, evaluation | Only prediction logic |
| Goal | Insight + prediction | Prediction only |
This distinction is important for both learning and real world implementation.
Types of Classification Problems
1. Binary Classification: Two possible outcomes
- Example: Spam vs Not Spam
2. Multi Class Classification: More than two classes
- Example: Email categories
3. Multi Label Classification: Multiple labels per data point
- Example: Movie genres
Steps Involved in Classification Analysis
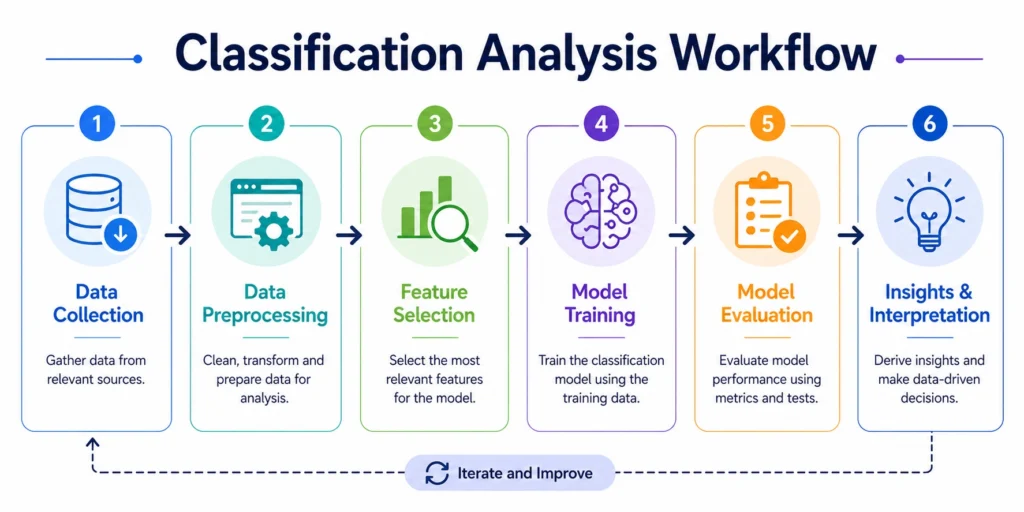
Classification analysis follows a structured pipeline:
- Data Collection: Gather labeled data relevant to the problem.
- Data Preprocessing: Handle missing values and encode categorical variables with Scale features
- Feature Selection: Select important features to improve model accuracy.
- Model Selection (Algorithms):
- Choose suitable classification algorithms such as:
- Logistic Regression
- Decision Trees
- KNN
- SVM
- Random Forest
- Choose suitable classification algorithms such as:
Model Training: Train the model using training data.
Model Evaluation: Evaluate using metrics like: Accuracy, Precision, Recall and F1 Score.
Interpretation & Insights: Understand results and extract meaningful insights.
Key Concepts in Classification Analysis
1. Features and Labels
- Features → Inputs
- Labels → Output categories
2. Decision Boundary
- Separates different classes in the dataset.
3. Overfitting and Underfitting
- Overfitting → Model memorizes data
- Underfitting → Model fails to learn
4. Bias Variance Tradeoff
- Balancing model complexity and performance.

Evaluation Metrics (Why They Matter in Analysis)
Unlike just running an algorithm, classification analysis focuses on how well the model performs.
- Accuracy → Overall correctness
- Precision → Correct positive predictions
- Recall → Coverage of actual positives
- F1 Score → Balance of precision & recall
- Confusion Matrix → Detailed performance breakdown
Practical Implementation in Python
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import classification_report
import pandas as pd
# Sample dataset
data = {
'Feature': [1,2,3,4,5,6,7,8],
'Target': [0,0,0,1,1,1,1,1]
}
df = pd.DataFrame(data)
X = df[['Feature']]
y = df['Target']
# Split data
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
# Model
model = LogisticRegression()
model.fit(X_train, y_train)
# Predictions
y_pred = model.predict(X_test)
print(classification_report(y_test, y_pred))
Real World Applications of Classification Analysis
- Fraud Detection: Identify suspicious transactions
- Healthcare Diagnosis: Predict diseases based on symptoms
- Email Filtering: Spam vs non spam classification
- Customer Segmentation: Group users based on behavior
- Image Recognition: Classify objects in images
Common Mistakes in Classification Analysis….
- Focusing only on algorithms
- Ignoring data preprocessing
- Using wrong evaluation metrics
- Not handling class imbalance
- Skipping feature engineering
Most errors happen before or after the algorithm stage.
Why Classification Analysis Matters
Classification analysis is important because it:
- Provides end to end understanding
- Improves decision making
- Helps build robust models
- Enables business insights
It is not just about prediction, but about understanding data and improving outcomes.
So the final verdict is….
Classification analysis in machine learning goes beyond simply applying algorithms, it is a complete workflow that involves understanding data, preparing it, selecting the right models, and evaluating results effectively.
- While classification algorithms play an important role, they are only one part of the overall analytical process.
- By focusing on the full classification analysis pipeline, you can build more accurate, reliable, and meaningful machine learning solutions that work effectively in real world scenarios.

Frequently Asked Questions
Answer:
Classification analysis in machine learning is the complete process of analyzing data, applying models, and evaluating results to classify data into categories.
Answer:
No, classification analysis is a broader process that includes data preparation, model selection, evaluation, and interpretation, while algorithms are just one part of it.
Answer:
Steps include data collection, preprocessing, feature selection, model training, evaluation, and interpretation.
Answer:
It helps in predicting categories and extracting meaningful insights for decision making.
Answer:
Spam detection, fraud detection, and disease prediction are common examples.features, which can lead to higher dimensionality.

