
Generative Adversarial Network
What is a Generative Adversarial Network (GAN)?
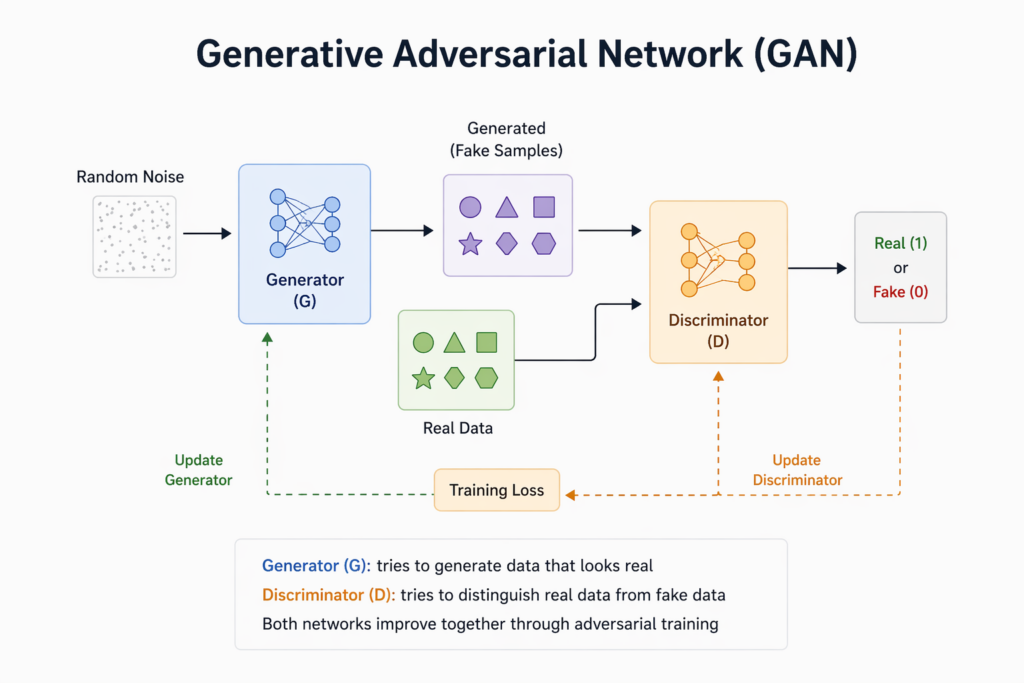
A Generative Adversarial Network (GAN) is an advanced machine learning model used to create new data that looks realistic, such as images, audio, or videos. It works using two neural networks that compete with each other one generates data while the other evaluates it. This “adversarial” process helps improve the quality of the generated content over time.
GANs are widely used today for tasks like image generation, content creation, and data simulation due to their ability to produce highly realistic results.

How Do These Neural Systems Work Together?
- Imagine two artists locked in a creative battle. One is a forger trying to replicate masterpieces, and the other is an expert critic trained to spot fakes. The forger attempts to create paintings that are indistinguishable from the originals, while the critic scrutinizes each attempt, pointing out flaws and rejecting anything that doesn’t meet the standard.
- This dynamic is a simplified analogy of how two interconnected neural systems operate during training. One of them is designed to generate new data whether it’s an image, audio, or even text that mimics a given dataset.
- The generator begins with random noise and gradually learns to produce output that increasingly resembles the real examples it’s trying to emulate.
- On the other side, the evaluator is simultaneously learning as well. It’s exposed to both real data and the outputs from the generator. Its task is to become better at telling the difference between the two.
- This constant feedback loop is what drives the progress. The generator learns not by directly comparing its output to real data, but by trying to fool the evaluator.
Why Are They Called Adversarial?
The word adversarial reflects the unique training strategy at the heart of this system one inspired directly by game theory. In simple terms, two neural networks are set up as opponents in a game. Each has a clear objective, and both are constantly trying to outsmart the other.
The system consists of two players:
- A creator network (generator), which tries to produce data that looks real.
- A judge network (discriminator), which tries to determine whether the data is real or fake.
- The generator’s goal:
Fool the discriminator by producing highly realistic data. - The discriminator’s goal:
Accurately identify whether the input is genuine or artificially created. - This setup forms a classic minimax game
- One player’s gain is the other’s loss.
- The generator minimizes its loss by improving its output.
- The discriminator maximizes its accuracy by sharpening its detection skills.
The adversarial nature drives performance:
- The generator becomes better at mimicking real data.
- The discriminator becomes more skilled at detecting fakes.
- Over time, the generator improves to the point where the discriminator can no longer reliably distinguish between real and generated data.
- This dynamic competition encourages innovation, much like natural selection or economic strategy games.
- Without this adversarial feedback loop, the system wouldn’t evolve or improve as effectively.
- The approach is rooted in strategic adaptation, making the learning process both efficient and creative.
- In the end, this rivalry results in extremely high quality, realistic outputs all thanks to the constant push and pull between the two networks.
- Capable of producing high-quality, realistic outputs.
- Require minimal supervision once training begins.
- Excellent for unsupervised learning tasks.
- Can enhance data privacy by generating synthetic datasets.
- Versatile applicable across industries like fashion, healthcare, and gaming.


Key Components of a GAN Generator vs. Discriminator
To understand how these networks function, it’s important to explore the two core components that drive their learning process the generator and the discriminator. These two networks work in opposition yet are deeply interconnected. Their relationship forms the basis of the entire architecture and training process.
1. The Generator:
The generator is essentially responsible for creating new data. Think of it as a digital artist attempting to recreate a masterpiece from scratch, with no direct reference to the original only feedback from a critic.
Key roles and characteristics:
- Starts with random noise:
The input to the generator is usually a vector of random numbers, sometimes called a “latent vector.” It doesn’t represent anything meaningful at first. - Transforms noise into synthetic data:
Through a series of transformations (using layers like convolutional and deconvolutional layers), it converts the random input into structured data such as an image, audio clip, or other formats depending on the task. - Learns to mimic real data distribution:
Over time, and with feedback from the discriminator, the generator improves its ability to produce outputs that resemble real examples from the dataset. - Goal:
Fool the discriminator by generating content that is as realistic as possible.
2. The Discriminator:
The discriminator is like a seasoned art critic or fraud detector. It evaluates the quality of data it sees and judges whether it comes from the real dataset or has been generated artificially.
Key roles and characteristics:
- Receives both real and fake inputs:
It is fed a mix of actual data samples and outputs from the generator. It doesn’t know which is which in advance. - Outputs a probability score:
The discriminator produces a value usually between 0 and 1 representing the probability that the input data is real (from the actual dataset) or fake (from the generator). - Trains to distinguish real from fake:
Using a process of backpropagation, the discriminator adjusts its internal parameters to improve its accuracy in identifying fake data. - Goal:
Successfully identify which inputs are real and which are synthetic.
The Feedback Loop
What makes this system powerful is the adversarial training loop:
- The generator improves by analyzing the discriminator’s feedback.
- The discriminator sharpens its ability as the generator becomes more skilled.
- Both networks are locked in a game where each one’s progress pushes the other to get better.
- Generating artworks and deepfake videos.
- Creating realistic virtual environments for games and simulations.
- Enhancing low resolution images (super resolution).
- Generating synthetic data for training machine learning models.
- Style transfer in photography and video editing.
Types of GANs
The field of artificial intelligence has seen tremendous growth, and one of the most fascinating developments is the rise of the Generative Adversarial Network (GAN). Since its introduction, this powerful machine learning architecture has evolved into many specialized variants, each designed to solve unique challenges or enhance specific capabilities especially in image synthesis, translation, and manipulation.
Let’s take a look at some of the most well known and widely used types of GANs that are shaping the future of creative AI and deep learning.
1. DCGAN (Deep Convolutional GAN)
DCGAN is one of the earliest and most foundational variants of the Generative Adversarial Network. It introduced a way to build both the generator and the discriminator using convolutional and convolutional transpose layers, which are particularly effective for handling image data.
Key Highlights:
- Uses deep convolutional networks instead of fully connected ones.
- Ideal for generating clear, visually coherent images.
- Improved training stability compared to early GAN models.
- Commonly used for research and educational purposes due to its simplicity and effectiveness.
DCGAN laid the groundwork for many of the advanced GAN architectures we see today by establishing best practices like using batch normalization and replacing pooling layers with strided convolutions.
2. CycleGAN
CycleGAN is designed for image to image translation without the need for paired datasets. That means it can learn to convert images from one domain to another even if there’s no direct correspondence between them. A popular example is translating photos of horses into zebras or turning summer landscapes into winter scenes.
Key Highlights:
- Works with unpaired image datasets.
- Uses cycle consistency loss to ensure the translation can be reversed.
- Great for style transfer, artistic filters, and domain adaptation tasks.
- Frequently used in medical imaging, art, and augmented reality applications.
CycleGAN opened up a whole new set of possibilities by allowing transformations between domains that are stylistically different but semantically related.
3. StyleGAN
StyleGAN, developed by NVIDIA, represents one of the most visually impressive breakthroughs in the GAN family. It is best known for creating hyper-realistic human faces that are almost indistinguishable from real photographs. You may have seen it in action on the website “This Person Does Not Exist.”
Key Highlights:
- Introduces a novel style based generator architecture.
- Separates high level attributes (like pose) from low level details (like freckles).
- Produces extremely high quality images with fine control over the output.
- Used in fashion design, gaming, avatars, and even deepfake content creation.
StyleGAN’s flexibility and photorealistic capabilities make it a popular choice for anyone looking to explore high quality synthetic media generation.
4. Pix2Pix
Unlike CycleGAN, Pix2Pix requires paired image datasets. It’s specifically designed for tasks where you have a clear before and after scenario, such as converting a black and white sketch into a fully colored version or turning a satellite image into a map.
Key Highlights:
- Requires aligned (paired) training images.
- Very effective for supervised image to image translation.
- Useful in applications like photo enhancement, face aging, or edge to photo tasks.
Pix2Pix is often used in creative tools and educational apps that need structured input-output relationships, making it a valuable resource in both tech and design.
5. BigGAN
BigGAN, another innovation from researchers at DeepMind, is optimized for large-scale, high-resolution image synthesis. It scales up both the model size and training dataset to generate images with exceptional detail and variety.
Key Highlights:
- Utilizes large batch sizes and high capacity models.
- Produces more diverse and sharper outputs compared to earlier GANs.
- Designed to generate high resolution images across multiple classes.
- Often used in tasks that demand visual richness and large scale realism.
BigGAN is particularly valuable in enterprise-level projects or scientific research where quality and scale are critical.
GANs Keep Evolving
Each of these variants builds upon the original idea behind the Generative Adversarial Network, adapting its structure and training methods to tackle specific problems. Whether it’s refining image resolution, transforming styles, or scaling up to more complex data distributions, there’s a specialized GAN model for nearly every need in the field of generative AI.
As the technology matures, we can expect even more powerful, creative, and ethical uses of GANs to emerge pushing the boundaries of what machines can generate.
Conclusion
Generative Adversarial Networks (GANs) have emerged as one of the most powerful innovations in artificial intelligence, capable of producing stunningly realistic content across various domains. By harnessing the adversarial relationship between the Generator and the Discriminator, GANs learn to create data that mimics reality with impressive accuracy. From revolutionizing digital art to generating synthetic datasets for research, the applications of GANs are vast and growing rapidly. As the technology evolves, we can expect Generative Adversarial Networks (GANs) to play an even greater role in shaping the future of AI driven creativity, problem-solving, and data generation.
Frequently Asked Questions
Answer:
A Generative Adversarial Network (GAN) is a machine learning model made up of two neural networks — a generator and a discriminator. The generator creates fake data, while the discriminator evaluates it against real data. This competition helps the system produce highly realistic outputs over time.
Answer:
A GAN works through an adversarial process where two models learn together. The generator tries to create realistic data, and the discriminator tries to detect whether the data is real or fake. As both improve, the generated results become increasingly accurate and lifelike.
Answer:
GANs are widely used in image generation, video creation, deepfake technology, and data augmentation. They also play a role in medical imaging, game design, and creative AI tasks like art and music generation. Their ability to mimic real data makes them highly versatile.
Answer:
GANs can generate highly realistic and high-quality synthetic data without requiring labeled datasets. They are powerful for creativity, simulation, and enhancing limited datasets. This makes them useful in scenarios where real data is scarce or expensive to obtain.
Answer:
Training GANs can be difficult due to instability and issues like mode collapse, where the generator produces limited variations. They also require significant computational power and careful tuning. Ensuring balanced training between the generator and discriminator is crucial for success.
Answer:
IBM Data Analytics refers to the use of data analysis techniques, tools, and methodologies to extract meaningful insights from structured and unstructured data. It is important because it helps organizations make data-driven decisions, improve efficiency, and identify trends that support business growth.
Answer:
To work in IBM Data Analytics, you need skills in data handling, statistical analysis, and visualization. Knowledge of tools like spreadsheets, programming languages, and data platforms is also helpful. Strong problem-solving and analytical thinking abilities are essential for interpreting data effectively.

