Feature Scaling and Normalization
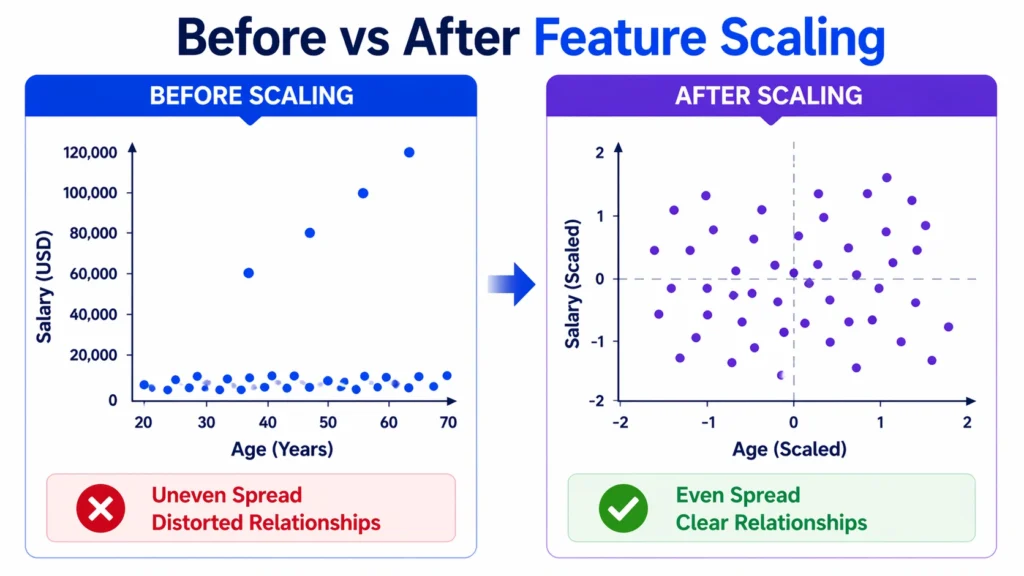
Normalization is a type of feature scaling where values are scaled to a fixed range, typically 0 to 1.
Formula (Min-Max Normalization):
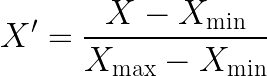
This ensures:
- All values lie between 0 and 1
- Data distribution is preserved proportionally
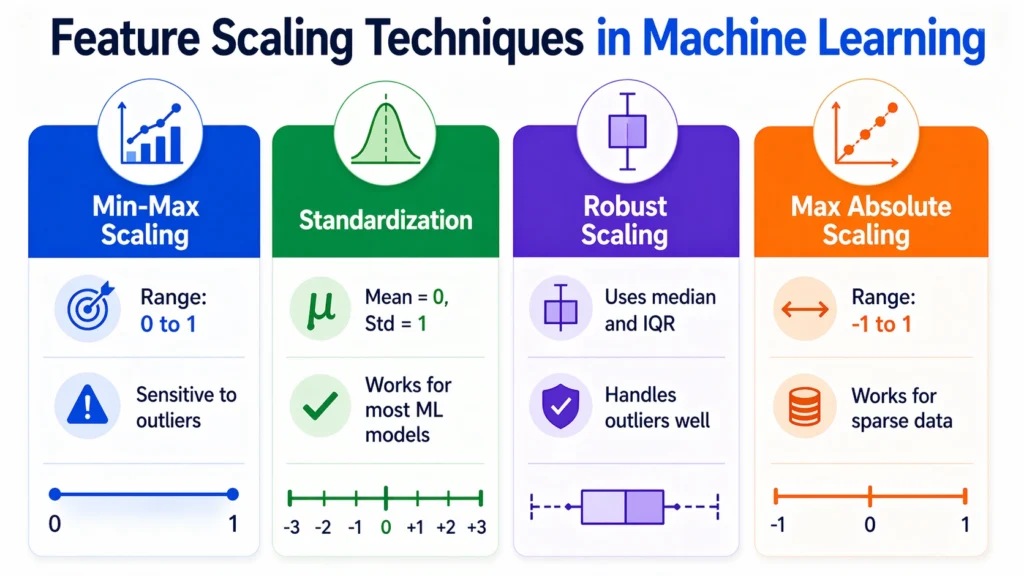
1. Min-Max Scaling (Normalization)
- Scales data between 0 and 1
- Sensitive to outliers
Example:
- If salary ranges from 10,000 to 100,000 → scaled between 0 and 1
2. Standardization (Z-score Normalization)
Transforms data to mean = 0 and standard deviation = 1
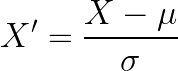
Less affected by outliers compared to Min-Max
3. Robust Scaling
- Uses median and interquartile range (IQR)
- Works well with outliers
4. Max Absolute Scaling
- Scales values between -1 and 1
- Useful for sparse datasets