
Huffman Coding in Python
Introduction to Huffman Coding
Huffman Coding stands as a fundamental technique in data compression, designed by David A. Huffman in 1952.
Its primary purpose lies in reducing the size of data to optimize storage and transmission efficiency. This ingenious algorithm assigns shorter codes to frequent symbols and longer codes to infrequent ones, effectively compressing data with variable-length codes.
Understanding to Huffman Coding
The main idea behind Huffman coding is to assign variable-length codes to input symbols, such as characters in a file or pixels in an image, in such a way that frequently occurring symbols are assigned shorter codes, while less frequent symbols are assigned longer codes.
Working Principle of Huffman Coding
Symbol Frequency and Encoding
Huffman Coding operates based on the frequency of symbols within the data. It starts by creating a frequency table to identify the occurrence of each symbol.
Constructing Huffman Tree
The next step involves constructing a Huffman tree, utilizing a priority queue or heap data structure. This tree is built based on the frequency of symbols, where lower frequency symbols reside higher in the tree.
Assigning Codes to Symbols
Following the construction of the Huffman tree, each symbol is assigned a unique binary code. Frequent symbols receive shorter codes, while less frequent symbols obtain longer codes.
Implementation of Huffman Coding in Python
Let’s break down the Huffman coding implementation in Python step by step:
HuffmanNode Class:
- The HuffmanNode class represents a node in the Huffman tree. Each node has a symbol (character) and a frequency. The lt method is defined to enable comparison between nodes based on their frequencies.
build_huffman_tree Function:
- This function takes the input data and builds a Huffman tree.
- It starts by counting the frequency of each symbol in the input data using the Counter class from the collections module.
- It then creates a heap of HuffmanNode instances, where each node represents a symbol and its frequency.
- The function repeatedly combines the two nodes with the lowest frequencies until only one node (the root of the Huffman tree) remains.
build_huffman_codes Function:
- This function traverses the Huffman tree and assigns binary codes to each symbol.
- It uses a recursive approach, appending ‘0’ for the left child and ‘1’ for the right child in the traversal path.
- The codes are stored in the codes dictionary, where the symbol is the key, and the Huffman code is the value.
huffman_encoding Function:
- This function takes the input data and returns the encoded data along with the Huffman tree’s root.
- It first builds the Huffman tree using build_huffman_tree.
- Then, it uses the tree to generate Huffman codes for each symbol in the input data using build_huffman_codes.
- Finally, it creates the encoded data by replacing each symbol with its corresponding Huffman code.
huffman_decoding Function:
- This function takes the encoded data and the Huffman tree’s root to decode the data.
- It starts from the root and traverses the tree based on the bits in the encoded data.
- When it reaches a leaf node (a node with a symbol), it appends the symbol to the decoded data and resets the traversal to the tree’s root.

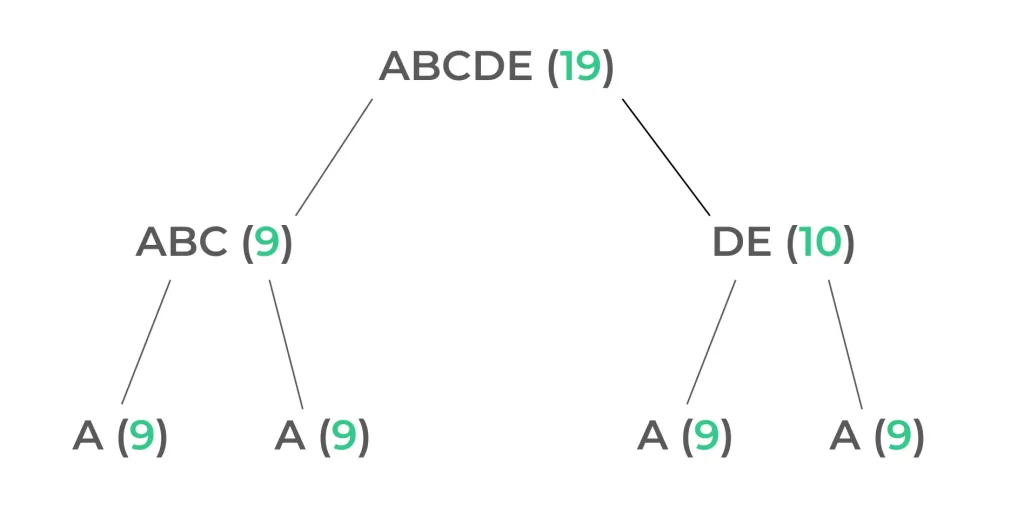
Huffman Tree Diagram
Huffman Tree Diagram Explanation
Learn DSA
Prime Course Trailer
Related Banners
Get PrepInsta Prime & get Access to all 200+ courses offered by PrepInsta in One Subscription
The Huffman tree is a binary tree where each node represents either a character from the input or a merged node (combination of characters) with their respective frequencies. The tree is constructed by repeatedly combining nodes with the lowest frequencies until a single root node is formed.
In this example, the characters A, B, C, D, and E from the given string “AABBBCCCCDDDDDEEEEE” are represented as individual nodes initially, each with its frequency:
- Node(A, 2): Represents character ‘A’ with a frequency of 2.
- Node(B, 3): Represents character ‘B’ with a frequency of 3.
- Node(C, 4): Represents character ‘C’ with a frequency of 4.
- Node(D, 5): Represents character ‘D’ with a frequency of 5.
- Node(E, 5): Represents character ‘E’ with a frequency of 5.
The merging process starts by combining the nodes with the lowest frequencies. It forms intermediate nodes, which gradually merge to build the final Huffman tree.
The steps of combining nodes based on frequency:
- Combine A and B: Creates a new node, Node(AB, 5), representing combined characters ‘A’ and ‘B’ with a frequency of 5.
- Combine Node(AB, 5) and C: Generates Node(ABC, 9), representing characters ‘A’, ‘B’, and ‘C’ with a frequency of 9.
- Combine Node(D, 5) and Node(E, 5): Forms Node(DE, 10) representing characters ‘D’ and ‘E’ with a frequency of 10.
- Combine Node(ABC, 9) and Node(DE, 10): Finally merges Node(ABC, 9) and Node(DE, 10) to create the root Node(ABCDE, 19), representing all characters with a frequency of 19.
Simple implementation of Huffman coding in Python.
import heapq
from collections import defaultdict, Counter
class HuffmanNode:
def __init__(self, symbol, frequency):
self.symbol = symbol
self.frequency = frequency
self.left = None
self.right = None
def __lt__(self, other):
return self.frequency < other.frequency def build_huffman_tree(data): frequency_counter = Counter(data) heap = [HuffmanNode(symbol, freq) for symbol, freq in frequency_counter.items()] heapq.heapify(heap) while len(heap) > 1:
left_child = heapq.heappop(heap)
right_child = heapq.heappop(heap)
internal_node = HuffmanNode(None, left_child.frequency + right_child.frequency)
internal_node.left = left_child
internal_node.right = right_child
heapq.heappush(heap, internal_node)
return heap[0]
def build_huffman_codes(node, current_code, codes):
if node.symbol is not None:
codes[node.symbol] = current_code
return
if node.left is not None:
build_huffman_codes(node.left, current_code + '0', codes)
if node.right is not None:
build_huffman_codes(node.right, current_code + '1', codes)
def huffman_encoding(data):
if not data:
return None, None
root = build_huffman_tree(data)
codes = {}
build_huffman_codes(root, '', codes)
encoded_data = ''.join(codes[symbol] for symbol in data)
return encoded_data, root
def huffman_decoding(encoded_data, root):
if not encoded_data or root is None:
return None
current_node = root
decoded_data = ''
for bit in encoded_data:
if bit == '0':
current_node = current_node.left
else:
current_node = current_node.right
if current_node.symbol is not None:
decoded_data += current_node.symbol
current_node = root
return decoded_data
# Example Usage:
data_to_encode = "hello, world!"
encoded_data, huffman_tree = huffman_encoding(data_to_encode)
print("Original data:", data_to_encode)
print("Encoded data:", encoded_data)
decoded_data = huffman_decoding(encoded_data, huffman_tree)
print("Decoded data:", decoded_data)
This code defines a simple Huffman coding implementation in Python, including functions for encoding and decoding.
Applications & Benefits of Huffman Coding:
Following are the applications of huffman Coding:
Simple implementation of Huffman decoding in Python.
def huffman_decoding(encoded_data, root):
if not encoded_data or root is None:
return None
# Special case: Tree with only one unique symbol
if root.left is None and root.right is None:
return root.symbol * len(encoded_data)
current_node = root
decoded_data = ''
for bit in encoded_data:
if bit == '0':
current_node = current_node.left
else:
current_node = current_node.right
if current_node.symbol is not None:
decoded_data += current_node.symbol
current_node = root
return decoded_data
Checks for edge cases: Returns None if input is empty or handles single-character trees specially.
Bitwise traversal: Reads each bit (0 or 1) to move left or right in the Huffman tree.
Symbol detection: When a leaf node is reached, adds the symbol to the output.
Resets to root: After each symbol, it starts again from the tree root.
To Wrap it up:
In conclusion, Huffman Coding in Python presents a powerful tool for data compression, offering an elegant and efficient solution to reduce file sizes without compromising data quality. Its adaptability and wide-ranging applications make it a cornerstone in various industries.
FAQs
Huffman Coding is a lossless data compression algorithm that reduces file size by assigning shorter binary codes to more frequent symbols. It’s used to optimize storage and transmission without losing any data.
It works by building a frequency-based Huffman tree, assigning binary codes to characters, and replacing each character in the data with its corresponding code to compress the data. Python implementations typically use heaps and recursion for this process.
Huffman Coding is used in formats like JPEG, MP3, and ZIP for compressing images, audio, and files efficiently. It plays a vital role in reducing data size across multiple industries.
Huffman Coding is best for data with variable symbol frequencies, like text and images. However, it may not be effective for data with uniform symbol distribution or already compressed files.
Get over 200+ course One Subscription
Courses like AI/ML, Cloud Computing, Ethical Hacking, C, C++, Java, Python, DSA (All Languages), Competitive Coding (All Languages), TCS, Infosys, Wipro, Amazon, DBMS, SQL and others


Login/Signup to comment