
Direct Address Tables in Python

Introduction to Direct Address Table in Data Structure
The Data Address table in Python, a specific implementation of hashing, offer an efficient way to access and manage data. In Python, you have the flexibility to create and manipulate tree structures for various applications.
Let’s jump into the article to know more about Direct Address Table in Python and also you will get to know about Hashing.
Understanding Direct Address Table in Python
In Python, Direct Address Tables, also known as key-indexed tables, are a simple but powerful implementation of hashing. In this method, each data element is assigned a unique index that corresponds directly to its key.
How Direct Address Table Work
Direct Address Table work by creating an array where each slot in the array corresponds to a possible key. The key is used as an index to directly access the data element associated with it.
Example of Data Address Table in Hashing
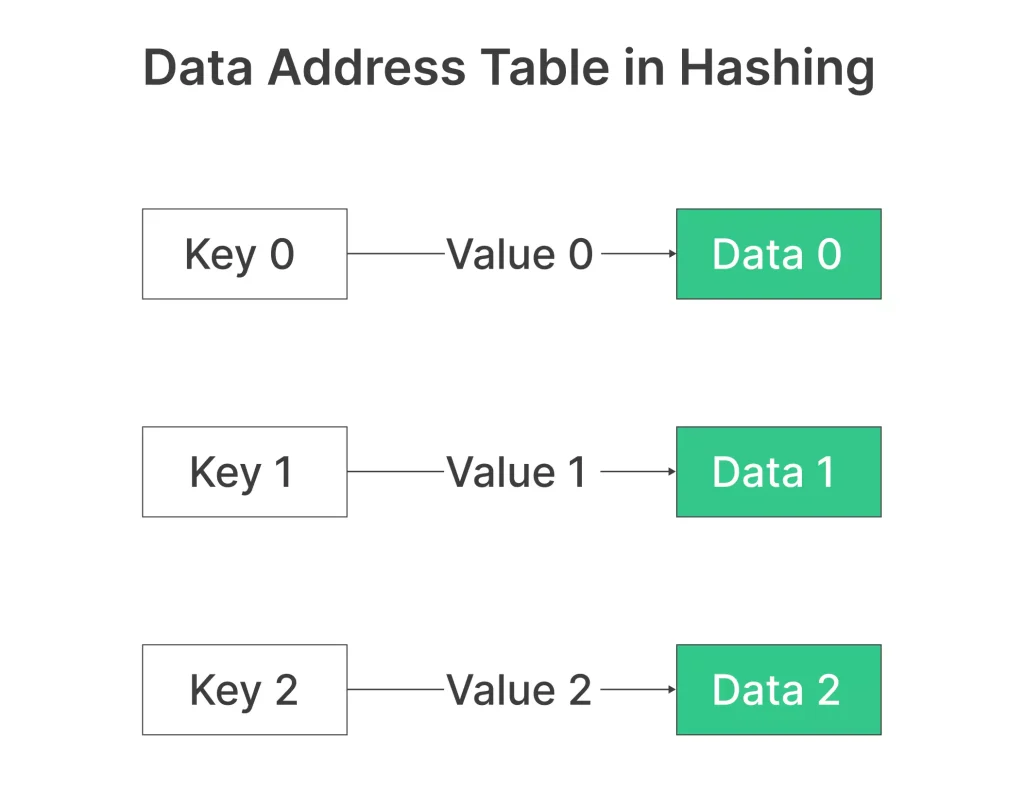
The core function of Direct Address Table
Data Storage: Direct Address Tables allocate a fixed-size array, where each slot or index in the array corresponds directly to a unique key. This establishes a direct mapping between keys and their associated data elements.
Data Retrieval: When you need to retrieve a specific data element, you simply use the key as an index to access the corresponding slot in the array. This direct access ensures rapid retrieval, making Direct Address Tables highly efficient for applications that require frequent data lookups.
Data Insertion and Deletion: To insert a new data element, you place it in the slot corresponding to its key. For deletion, you clear the slot associated with the key, effectively removing the element. Both operations have constant time complexity, ensuring efficient data management.
Structure of Direct Address Table
The structure of a Direct Address Table, also known as a Direct Addressing data structure, is quite straightforward. The basic structure of a Direct Address Table:
Array: The core of a Direct Address Table is an array (or list) of fixed size. The size of the array depends on the range of possible key values. For example, if the keys can be integers from 0 to 999, you would create an array of size 1000 to accommodate all possible keys.
Key-to-Index Mapping: In a Direct Address Table, the keys themselves are used as indices to access the associated data elements. Each unique key maps directly to a specific index in the array. For instance, if you have a key “K,” you would use “K” as the index to access the data element associated with that key.
Data Storage: Data elements or values are stored directly in the array at the index corresponding to their associated keys. If there is no associated data for a particular key, the corresponding slot in the array is left empty (often represented as None or null).
Representation of Direct Address Table structure in Python
# Initialize a Direct Address Table with a specific size direct_address_table = [None] * table_size # 'table_size' should match the range of possible keys # Insert data elements into the Direct Address Table direct_address_table[key1] = value1 direct_address_table[key2] = value2 # ... # Retrieve data elements based on keys data1 = direct_address_table[key1] data2 = direct_address_table[key2] # ... # Delete data elements direct_address_table[key1] = None direct_address_table[key2] = None # ...

Prime Course Trailer
Related Banners
Get PrepInsta Prime & get Access to all 200+ courses offered by PrepInsta in One Subscription
Direct Address Table Implementation
Direct Address Table implementation uses an array where keys act as direct indices, allowing constant-time insertion, deletion, and search. It is ideal for applications where the key universe is small and known in advance.
class DirectAddressTable:
def __init__(self, size):
# Create an array of a specified size, initialized with None
self.table = [None] * size
def insert(self, key, value):
# Ensure that the key is within the valid range of indices
if 0 <= key < len(self.table):
# Store the value at the index corresponding to the key
self.table[key] = value
else:
print("Error: Key is out of range.")
def retrieve(self, key):
# Ensure that the key is within the valid range of indices
if 0 <= key < len(self.table):
# Retrieve the value at the index corresponding to the key
return self.table[key]
else:
print("Error: Key is out of range.")
return None
def delete(self, key):
# Ensure that the key is within the valid range of indices
if 0 <= key < len(self.table):
# Clear the value at the index corresponding to the key
self.table[key] = None
else:
print("Error: Key is out of range.")
# Create a Direct Address Table with a size of 100
table_size = 100
dat = DirectAddressTable(table_size)
# Insert data elements with keys into the table
dat.insert(5, "Data A")
dat.insert(12, "Data B")
dat.insert(30, "Data C")
# Retrieve data elements using keys
data_a = dat.retrieve(5)
data_b = dat.retrieve(12)
data_c = dat.retrieve(30)
# Print the retrieved data
print("Data A:", data_a)
print("Data B:", data_b)
print("Data C:", data_c)
# Delete data element with a key
dat.delete(12)
# Attempt to retrieve deleted data
deleted_data = dat.retrieve(12)
print("Deleted Data (should be None):", deleted_data)
Output:
Data A: Data A Data B: Data B Data C: Data C Deleted Data (should be None): None
Explanation:
- DirectAddressTable class uses a list to store values where the index is the key.
- insert(key, value) places the value at the specified index if the key is valid.
- retrieve(key) returns the value at the index or None if the key is invalid or deleted.
- delete(key) removes the value by setting the index to None.
- The operations are performed in constant time for efficiency.
Time and Space Complexity:
| Operation | Time Complexity | Space Complexity |
|---|---|---|
| Insert | O(1) | O(1) |
| Retrieve | O(1) | O(1) |
| Delete | O(1) | O(1) |
| Initialization | O(n) | O(n) |
Difference between Direct Address Table and Hash Table
| Aspects | Direct Address Table | Hash Table |
|---|---|---|
Data Structure | In a Direct Address Table, each unique key maps directly to a specific index or slot in an array. The key itself serves as the index to access the associated data element. | In a Hash Table, a hash function is used to map keys to indices in the array. The hash function transforms the key into an index, allowing for efficient data retrieval. |
Space Complexity | The space complexity of a Direct Address Table is directly proportional to the range of possible keys. If the key space is large, it can result in significant memory consumption, even if not all keys are used. | Hash tables typically have a smaller array size compared to the key space, which can lead to more efficient memory usage. |
| Collision Handling | Direct Address Tables do not handle collisions well. If multiple keys map to the same index (collisions), they cannot coexist in the same slot. | Hash tables use collision resolution techniques to handle cases where multiple keys hash to the same index. |
| Complexity | Direct Address Tables offer constant-time complexity (O(1)) for insertion, retrieval, and deletion because they directly map keys to indices. | the worst-case complexity can be higher (O(n)) if many keys hash to the same index (collision). |
| Implementation | Implementation of Direct Address Tables is straightforward, especially when the key space is not excessively large. | Implementing hash tables requires designing an effective hash function and choosing a collision resolution strategy. |
The Advantages of Direct Address Table In Python
Final Thoughts:
We explored the fundamental concepts of Direct Address Tables are a powerful data structure that offers constant-time access and simplicity. They find applications in memory management, symbol tables, caching, and various other domains where fast data retrieval is essential. Understanding their advantages and implementation details is crucial for software engineers and computer scientists.
FAQs
A Direct Address Table is a simple data structure that uses an array where each index directly represents a key. It allows constant-time operations like insert, delete, and search if the key range is small and fixed.
Use a Direct Address Table when the universe of keys is small and each key is unique. Hash tables are better suited for large or sparse key ranges due to space efficiency.
The three main operations are insert(key, value), delete(key), and search(key), all of which work in O(1) time using direct indexing.
They consume large memory when the key universe is big, even if only a few keys are used. This makes them impractical for large or dynamic key sets.
Get over 200+ course One Subscription
Courses like AI/ML, Cloud Computing, Ethical Hacking, C, C++, Java, Python, DSA (All Languages), Competitive Coding (All Languages), TCS, Infosys, Wipro, Amazon, DBMS, SQL and others


Login/Signup to comment