
Dijkstra’s algorithm in Python
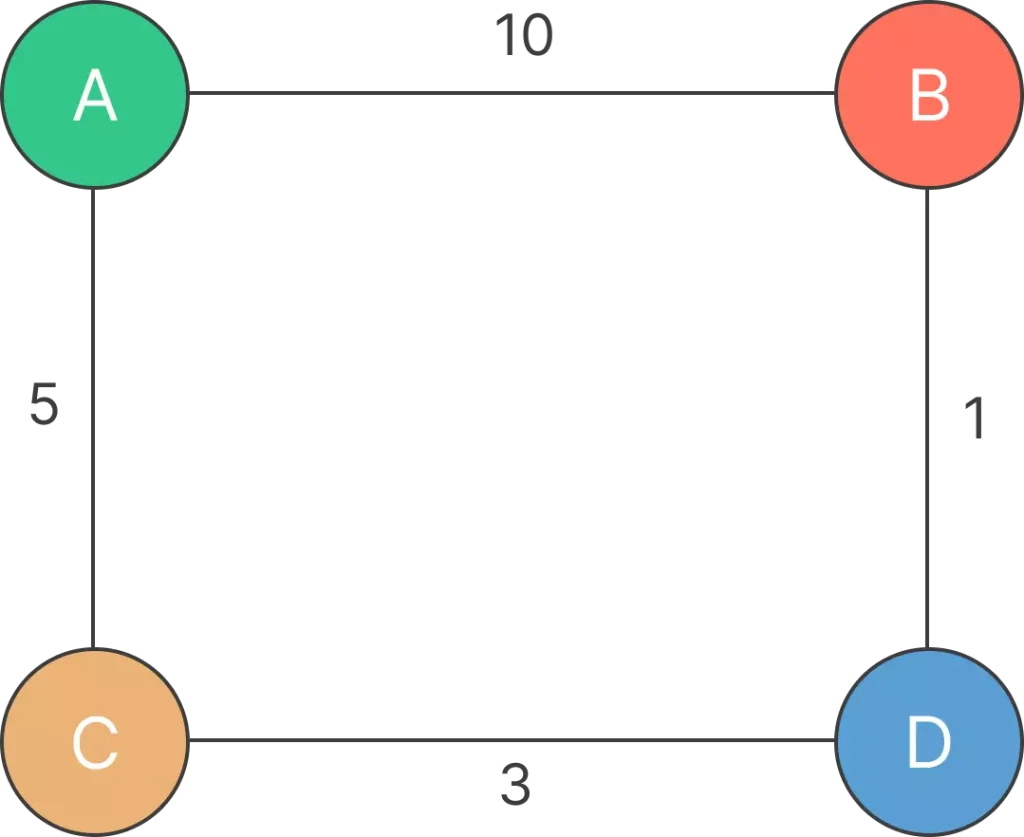
In this graph, nodes A, B, C, and D are connected by edges with the specified weights.
Step 1: Initialization:
- Mark all nodes as unvisited.
- Assign a tentative distance value to every node. Set the initial node’s distance to 0 and all other nodes’ distances to infinity.
- Set the initial node (A) as the current node.
A: 0
B:
C:
D:
B:

C:
D:
Step 2: Iteration:
- Iteration 1: Consider neighbors of A (B and C).
- For B: The tentative distance from A to B is 0 (current distance to A) + 10 (weight of AB edge) = 10. Update B’s distance.
- For C: The tentative distance from A to C is 0 (current distance to A) + 5 (weight of AC edge) = 5. Update C’s distance.
- Iteration 1: Consider neighbors of A (B and C).
Updated distances: A: 0, B: 10, C: 5, D: ∞
- Iteration 2: Choose the node with the smallest tentative distance (C).
- Consider neighbors of C (A, D).
- For A: The tentative distance from C to A is 5 (current distance to C) + 5 (weight of CA edge) = 10. No update needed for A.
- For D: The tentative distance from C to D is 5 (current distance to C) + 3 (weight of CD edge) = 8. Update D’s distance.
Updated distances: A: 0, B: 10, C: 5, D: 8
- Iteration 3: Choose the node with the smallest tentative distance (D).
- Consider neighbors of D (B).
- For B: The tentative distance from D to B is 8 (current distance to D) + 1 (weight of DB edge) = 9. No update needed for B.
Updated distances: A: 0, B: 9, C: 5, D: 8
Step 3: Termination:
- All nodes have been visited.
Step 4: Path Reconstruction (Optional):
- The shortest paths from A to other nodes can be reconstructed. For example, the shortest path to node B is A -> C -> D -> B with a total weight of 9.




Login/Signup to comment