
Collision in Hashing

Introduction to Collision Handling in Hashing
Hashing is a fundamental concept used to efficiently store and retrieve data. Hashing algorithms play a crucial role in various applications, including data retrieval, encryption, and security.
Let’s jump into the article to know more about Collision Handling in Hashing and also you will get to know about the potential issue that can occur in the process – collisions in hashing in Python.
Understanding Collision Handling in Hashing
Collision in hashing occurs when two different pieces of data produce the same hash value. This can happen due to the finite size of the hash table and the infinite number of possible data inputs. Collisions are a common challenge in hash tables, and they need to be managed effectively to maintain the integrity of the data structure.
Collision in Hashing in Python with Example
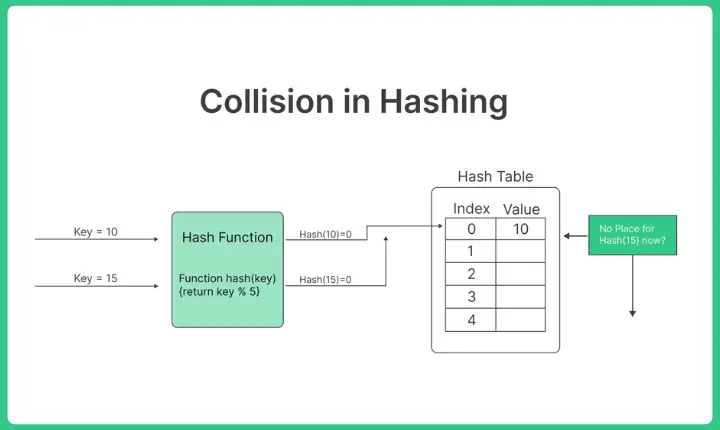
Collision Handling Techniques
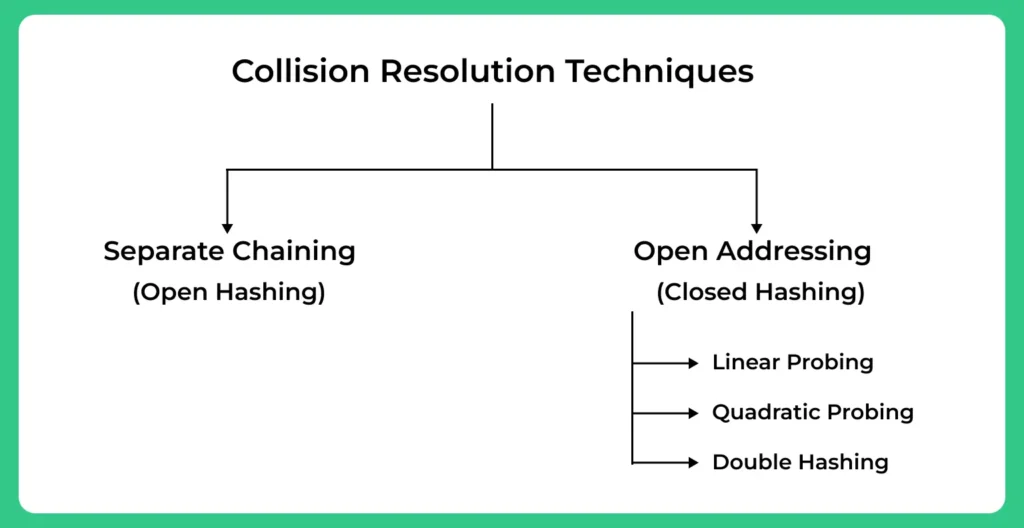
- Open Addressing
- Separate Chaining
Open Addressing
Open addressing is a collision resolution technique in which the system searches for the next available slot within the hash table when a collision occurs. This method involves linear probing, quadratic probing, and double hashing, among others.
Implementation of Open Addressing Collision in Python
class HashTable:
def __init__(self, size):
self.size = size
self.table = [None] * size
def hash_function(self, key):
return hash(key) % self.size
def insert(self, key, value):
index = self.hash_function(key)
while self.table[index] is not None:
index = (index + 1) % self.size
self.table[index] = (key, value)
def search(self, key):
index = self.hash_function(key)
while self.table[index] is not None:
if self.table[index][0] == key:
return self.table[index][1]
index = (index + 1) % self.size
return None
def delete(self, key):
index = self.hash_function(key)
while self.table[index] is not None:
if self.table[index][0] == key:
self.table[index] = None
return
index = (index + 1) % self.size
def display(self):
for i in range(self.size):
if self.table[i] is not None:
print(f"Index {i}: {self.table[i][0]} => {self.table[i][1]}")
# Example usage:
hash_table = HashTable(10)
hash_table.insert("apple", 5)
hash_table.insert("banana", 7)
hash_table.insert("cherry", 9)
hash_table.display()
print(hash_table.search("cherry"))
hash_table.delete("banana")
hash_table.display()
Output:
Index 0: banana => 7
Index 4: cherry => 9
Index 5: apple => 5
Output:
Index 4: cherry => 9
Index 5: apple => 5
Explanation :
In this Python code, we’ve created a simple HashTable class with methods for insertion, search, and deletion using linear probing for collision resolution.
- __init__: Initializes the hash table with a specified size.
- hash_function: Computes the hash index for a given key.
- insert: Inserts a key-value pair into the hash table, handling collisions using linear probing.
- search: Searches for a key in the hash table and returns its associated value.
- delete: Deletes a key-value pair based on the key.
- display: Displays the contents of the hash table.

Advantages of Open Addressing
Separate Chaining
Separate chaining, also known as closed addressing, involves creating a linked list at each index in the hash table. When collisions happen, the data is simply added to the linked list at the corresponding index.
Implementation of Separate Chaining Collision in Python
class HashTable:
def __init__(self, size):
self.size = size
self.table = [None] * size
def hash_function(self, key):
return hash(key) % self.size
def insert(self, key, value):
index = self.hash_function(key)
if self.table[index] is None:
self.table[index] = [(key, value)]
else:
# Collision occurred, add to the linked list at this index
self.table[index].append((key, value))
def search(self, key):
index = self.hash_function(key)
if self.table[index] is not None:
for k, v in self.table[index]:
if k == key:
return v
# Key not found
return None
def delete(self, key):
index = self.hash_function(key)
if self.table[index] is not None:
for item in self.table[index]:
if item[0] == key:
self.table[index].remove(item)
return
def display(self):
for i in range(self.size):
if self.table[i] is not None:
for key, value in self.table[i]:
print(f"Index {i}: {key} => {value}")
# Example usage:
hash_table = HashTable(10)
hash_table.insert("apple", 5)
hash_table.insert("banana", 7)
hash_table.insert("cherry", 9)
hash_table.display()
# Output:
# Index 0: apple => 5
# Index 1: None => None
# Index 2: None => None
# Index 3: None => None
# Index 4: None => None
# Index 5: None => None
# Index 6: None => None
# Index 7: None => None
# Index 8: None => None
# Index 9: None => None
# Index 1: banana => 7
# Index 9: cherry => 9
print(hash_table.search("cherry")) # Output: 9
hash_table.delete("banana")
hash_table.display()
# Output:
# Index 0: apple => 5
# Index 1: None => None
# Index 2: None => None
# Index 3: None => None
# Index 4: None => None
# Index 5: None => None
# Index 6: None => None
# Index 7: None => None
# Index 8: None => None
# Index 9: None => None
# Index 9: cherry => 9
Explanation :
In this Python code, we’ve created a simple HashTable class with methods for insertion, search, and deletion using linear probing for collision resolution.
- __init__: Initializes the hash table with a specified size.
- hash_function: Computes the hash index for a given key.
- insert: Inserts a key-value pair into the hash table. If a collision occurs, it adds the pair to a linked list at the same index.
- search: Searches for a key in the hash table and returns its associated value.
- delete: Deletes a key-value pair based on the key.
- display: Displays the contents of the hash table.
Advantages of Separate Chaining
To summarize
Collision in Hashing in Python is a key challenge that impacts the efficiency of hash-based data structures. While collisions cannot be entirely avoided, techniques like chaining and open addressing help manage them effectively, ensuring fast and reliable data access.
Understanding how Python handles collisions internally, along with regularly optimizing hash functions, enables developers to write more efficient and robust code, minimizing performance issues caused by collisions.
FAQs
Collisions occur because multiple keys can produce the same hash value due to the finite range of hash values.
Separate chaining is a collision handling strategy where each slot in the hash table holds a linked list of key-value pairs.
Open addressing methods involve finding the next available slot when a collision occurs, using techniques like linear probing or quadratic probing.
Collision handling is essential to ensure efficient data retrieval and maintain data integrity in hash tables.
Get over 200+ course One Subscription
Courses like AI/ML, Cloud Computing, Ethical Hacking, C, C++, Java, Python, DSA (All Languages), Competitive Coding (All Languages), TCS, Infosys, Wipro, Amazon, DBMS, SQL and others

