
Types of Clustering Algorithms
Types of Clustering Algorithms in Machine Learning
K-Means, Hierarchical, DBSCAN & More
Types of clustering algorithms in machine learning are essential for grouping similar data points without using labeled data. Clustering is a core technique in unsupervised learning, widely used in data analytics for pattern discovery, segmentation, and anomaly detection.
From simple methods like K Means to advanced techniques like DBSCAN and hierarchical clustering, each algorithm works differently depending on the structure of the dataset.
What are Clustering Algorithms in Machine Learning?
Clustering algorithms are techniques used to group data points based on similarity.
- No labeled data required
- Finds hidden patterns
- Groups similar observations together
Why Different Types of Clustering Algorithms Exist
No single clustering algorithm works best for all datasets.
Different algorithms are designed to:
- Handle different data distributions
- Work with noise or outliers
- Identify clusters of various shapes and sizes
Choosing the right algorithm improves accuracy and insights.
Types of Clustering Algorithms in Machine Learning
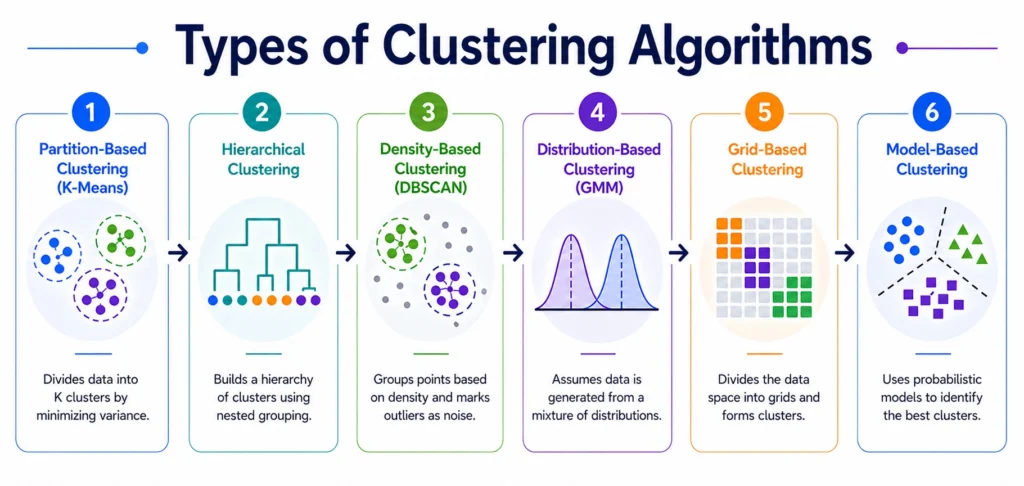
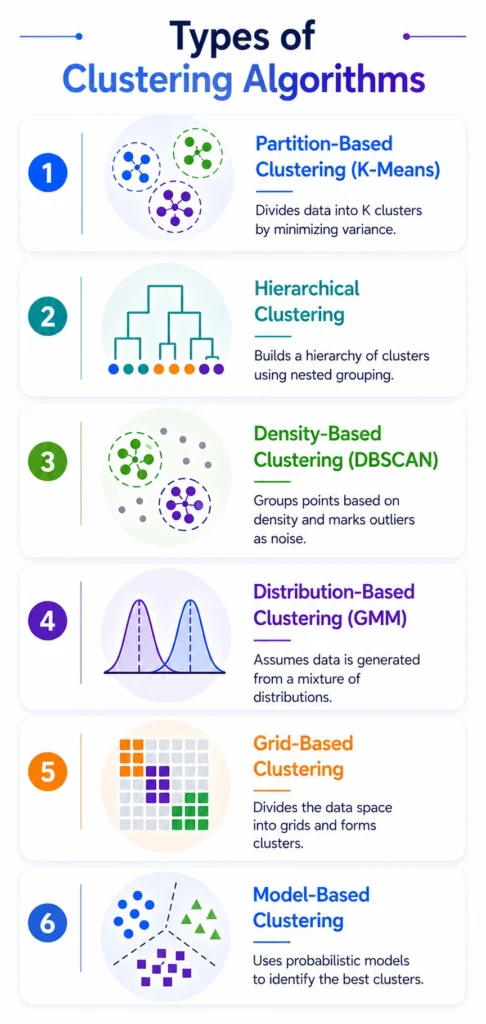
Clustering algorithms are broadly categorized into the following types:
1. Partition Based Clustering (K Means Clustering)
K Means Clustering: K Means is the most popular clustering algorithm.
How it works:
- Choose number of clusters (K) and Assign data points to nearest cluster
- Update cluster centroids and Repeat until convergence
Key Features:
- Fast and efficient, works well for large datasets
- Requires predefined number of clusters
Limitations: Sensitive to outliers and works best for spherical clusters
2. Hierarchical Clustering
Hierarchical clustering builds clusters in a tree like structure.
Types:
- Agglomerative (Bottom-Up)
- Divisive (Top-Down)
Key Features:
- No need to specify number of clusters initially
- Produces dendrogram (tree diagram)
Limitations: Computationally expensive and also not suitable for very large datasets
3. Density Based Clustering (DBSCAN)
DBSCAN groups data based on density.
How it works:
- Identifies dense regions
- Separates noise/outliers
Key Features:
- Handles arbitrary cluster shapes
- Detects noise effectively
Limitations: Sensitive to parameter selection and struggles with varying density.
4. Distribution Based Clustering (Gaussian Mixture Model)
Assumes data follows a probability distribution.
Key Features:
- Flexible cluster shapes
- Provides probabilistic clustering
Limitations: Computationally complex also requires assumption about distribution.
5. Grid Based Clustering
Divides data space into grids. Fast processing and orks well with large datasets.
Example: STING algorithm
6. Model Based Clustering
Uses mathematical models to define clusters. Having high flexibility and suitable for complex datasets.
Comparison of Clustering Algorithms
| Algorithm | Type | Best For | Limitation |
|---|---|---|---|
| K-Means | Partition | Large datasets | Needs K value |
| Hierarchical | Tree-based | Small datasets | Slow |
| DBSCAN | Density-based | Noise handling | Parameter sensitive |
| GMM | Distribution | Complex clusters | Computationally heavy |

Practical Implementation (K-Means Example in Python)
from sklearn.cluster import KMeans
import numpy as np
# Sample data
X = np.array([[1,2], [1,4], [1,0],
[10,2], [10,4], [10,0]])
# Model
kmeans = KMeans(n_clusters=2)
kmeans.fit(X)
print("Labels:", kmeans.labels_)
print("Centroids:", kmeans.cluster_centers_)
Real World Applications of Clustering Algorithms
- Customer Segmentation: Group users based on behavior
- Recommendation Systems: Suggest products based on similar users
- Fraud Detection: Identify unusual patterns
- Image Segmentation: Group pixels for image processing
- Social Network Analysis: Detect communities
How to Choose the Right Clustering Algorithm?
Choose based on:
- Dataset size
- Data distribution
- Presence of noise
- Required accuracy
Example:
- Use K Means → large datasets
- Use DBSCAN → noisy data
- Use hierarchical → small datasets
Common Mistakes to Avoid
- Choosing wrong number of clusters
- Ignoring data scaling
- Not handling outliers
- Using inappropriate algorithm
So the final verdict is….
Understanding the types of clustering algorithms in machine learning is essential for analyzing unlabeled data and extracting meaningful insights. Algorithms like K Means, hierarchical clustering, and DBSCAN each have unique strengths and use cases.
By selecting the right clustering method based on the dataset and problem requirements, you can improve model performance and uncover hidden patterns effectively. Clustering remains a powerful tool in data analytics, helping businesses make smarter, data driven decisions.

Frequently Asked Questions
Answer:
Types include K Means, hierarchical clustering, DBSCAN, and Gaussian mixture models.
Answer:
K Means is a partition based clustering algorithm that groups data into K clusters based on similarity.
Answer:
It builds clusters in a tree like structure using merging or splitting methods.
Answer:
DBSCAN is a density based clustering algorithm that identifies clusters and detects noise.
Answer:
There is no single best algorithm, it depends on dataset type and problem.

