
What is Support Vector Machine ?
What is Support Vector Machine ? (SVM)
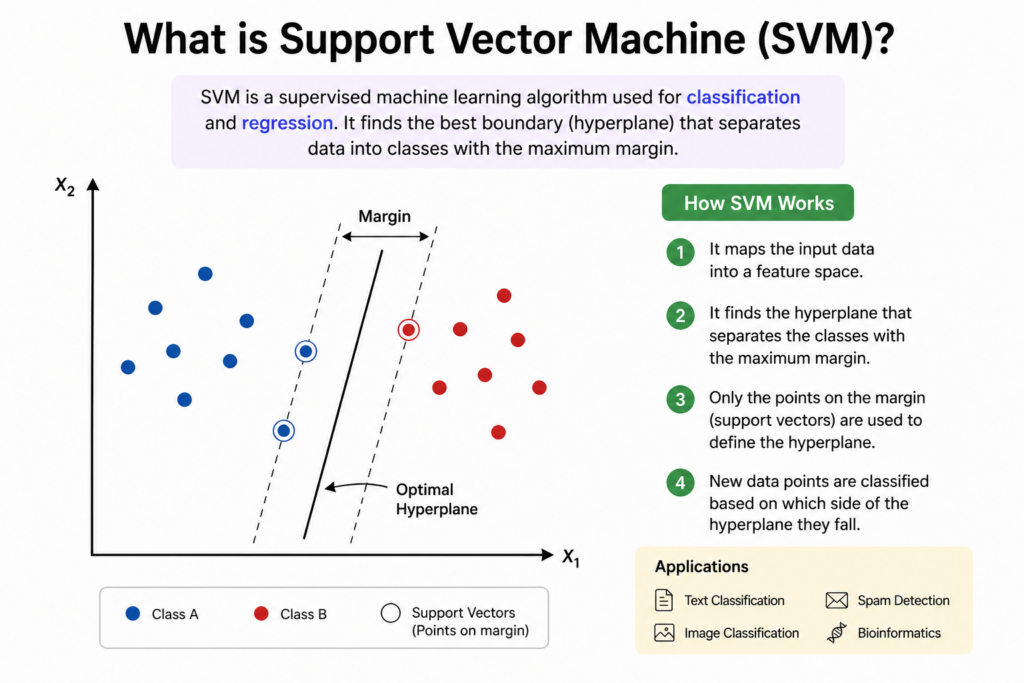
What is Support Vector Machine? Simply, its a supervised learning model that identifies the best decision boundary called a hyperplane to separate different classes of data points.
Now what do you mean by SVM in machine learning? It is widely applied in various fields such as image classification, text recognition, and medical diagnosis. By using kernel functions, SVM can handle both linear and non linear datasets, making it a versatile and efficient tool for predictive modeling.
In this article, we will explore how SVM works, its key concepts, and why it is one of the most reliable algorithms for complex classification problems.

Understanding Support Vector Machines (SVMs)
- Support Vector Machines (SVMs) are a type of supervised machine learning algorithm used for classification and regression tasks.
- They are particularly useful for complex datasets where clear decision boundaries are needed.
- SVMs work by finding the optimal hyperplane that best separates different classes in a dataset.
- These algorithms are widely used in areas such as image recognition, text classification, and medical diagnosis.
How SVM Works
- SVMs classify data by drawing a boundary (called a hyperplane) between different classes.
- The goal is to find the hyperplane that maximizes the margin between the closest data points from each class.
- These closest points are called support vectors, and they help define the boundary.
Components of Support Vector Machines
- Hyperplane – The decision boundary that separates different classes. In two dimensions, it is a line, while in three dimensions, it becomes a plane.
- Support Vectors – The data points closest to the hyperplane, which influence its position and orientation.
- Margin – The distance between the hyperplane and the nearest support vectors. A larger margin leads to better generalization and reduces the risk of overfitting.
Implementing SVM in Python (Using Scikit Learn)
SVMs can be easily implemented using the Scikit-Learn library in Python.
Below is a basic example demonstrating how to train an SVM classifier:
from sklearn.svm import SVC
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# Generate sample data
data, labels = make_classification(n_samples=100, n_features=5)
X_train, X_test, y_train, y_test = train_test_split(data, labels, test_size=0.2, random_state=42)
# Train an SVM model
model = SVC(kernel='linear')
model.fit(X_train, y_train)
# Make predictions
y_pred = model.predict(X_test)
print("Accuracy:", accuracy_score(y_test, y_pred))
Explanation of Code:
Generate sample data – We create a synthetic dataset with features and labels.
Split data into training and test sets – This ensures the model is trained on one set and evaluated on another.
Train the SVM model – We use a linear kernel for simplicity.
Make predictions and evaluate accuracy – The accuracy score measures how well the model classifies new data.


Types of Support Vector Machines
Support Vector Machine (SVM) is a supervised learning algorithm used for classification and regression. Based on how the data is distributed, SVM can be categorized into two main types:
1. Linear SVM
Linear SVM is used when the dataset is linearly separable, meaning that a straight line (in two dimensions) or a hyperplane (in higher dimensions) can effectively separate the different classes.
How Linear SVM Works?
Algorithm finds an optimal hyperplane that maximizes the margin between the two classes.
Margin is the distance between the hyperplane and the nearest data points (called support vectors).
Goal is to achieve the widest margin to ensure better generalization on unseen data.
Mathematical Representation
A hyperplane in an n – dimensional space is given by:
w · x + b = 0
where:
- w is the weight vector,
- x is the input feature vector,
- b is the bias term.
The optimization problem aims to minimize || w^2 || while ensuring correct classification of all training samples.
Example Use Cases of Linear SVM:
- Spam detection (Classifying emails as spam or not spam)
- Sentiment analysis (Positive vs. negative reviews)
- Medical diagnosis (Classifying patients as having a disease or not)
2. Non Linear SVM
Non-Linear SVM is used when the dataset is not linearly separable meaning that no straight line or hyperplane can separate the classes effectively.
How Non Linear SVM Works?
It uses kernel functions to transform the original data into a higher dimensional space where it becomes linearly separable.
Once mapped to the higher-dimensional space, a linear hyperplane is found to separate the transformed data.
Kernel Trick
Instead of explicitly transforming data into a higher dimension (which can be computationally expensive), SVM applies a kernel function that computes dot products in the transformed space without explicitly performing the transformation.
Common Kernel Functions:
Polynomial Kernel: Useful when the decision boundary is curved.
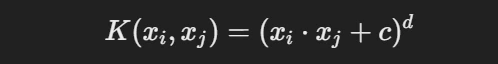
- d controls the degree of the polynomial.
2. Radial Basis Function (RBF) Kernel: Commonly used for complex, non-linear data.
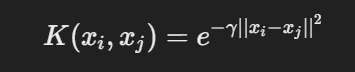
- γ controls the spread of the decision boundary.
3. Sigmoid Kernel: Similar to neural networks, used for binary classification.

Example Use Cases of Non-Linear SVM:
Image classification (Handwritten digit recognition, object detection)
Bioinformatics (DNA sequence classification)
Fraud detection (Identifying fraudulent transactions with complex patterns)
Difference between Linear and Non Linear Support Vector Machine
| Feature | Linear SVM | Non-Linear SVM |
|---|---|---|
| Data Distribution | Works when data is linearly separable | Works when data is not linearly separable |
| Decision Boundary | Straight line/hyperplane | Curved, more complex |
| Computational Complexity | Fast and efficient | Higher computational cost |
| Kernel Function | Not required | Required for mapping to higher dimensions |
| Example Use Cases | Spam detection, medical diagnosis | Image classification, fraud detection |
The Kernel Trick
The kernel trick allows SVM to operate in higher dimensions without explicitly transforming the data.
Common kernel functions include:
Linear Kernel – Used when data is linearly separable.
Polynomial Kernel – Suitable for curved decision boundaries, using polynomial equations to define separation.
Radial Basis Function (RBF) Kernel – Effective for complex, non-linear patterns by measuring similarity between data points.
Sigmoid Kernel – Behaves similarly to a neural network and is used for specialized tasks.
Choosing the right kernel function is important as it directly affects the model’s accuracy and performance.
Advantages of SVM
Effective in high-dimensional spaces – Works well with datasets that have many features, making it useful for text and image classification.
Robust to overfitting – Especially when proper kernel functions and parameters are used, preventing the model from memorizing noise in the data.
Versatile – Can be used for both classification and regression problems.
Works well with small datasets – Unlike deep learning models, SVM does not require a large amount of data to perform well.
Disadvantages of SVM
Computationally expensive – Training can be slow for large datasets, particularly when using complex kernels.
Difficult to interpret – Complex decision boundaries are harder to understand and visualize.
Sensitive to parameter selection – Choosing the right kernel and hyperparameters (such as regularization and gamma) is crucial.
Less effective on very large datasets – Deep learning methods like neural networks might be a better choice for massive datasets with millions of records.
SVM for Regression (SVR)
Support Vector Regression (SVR) is a version of SVM used for predicting continuous values. It works by finding a function that fits within a margin of tolerance from the true data points. SVR is particularly useful in cases where data has noise and outliers, as it minimizes their impact on predictions.
Applications of SVR:
Stock market prediction – SVR can help analyze stock price movements.
Weather forecasting – It can predict temperature and climate changes.
Real estate price estimation – SVR models can help determine property values based on various factors.
Real World Applications of SVM
SVMs are used in various industries and applications, including:
Image classification – Used in facial recognition, object detection, and medical imaging.
Text categorization – Helps classify emails as spam or not, sentiment analysis, and topic detection.
Handwriting recognition – Used in OCR (Optical Character Recognition) to digitize handwritten text.
Bioinformatics – Helps analyze genetic data for disease prediction.
Fraud detection – Banks and financial institutions use SVM to detect fraudulent transactions.
Conclusion
- Support Vector Machines are powerful tools for classification and regression tasks. Their ability to work with complex datasets makes them popular in various applications.
- While they have some limitations, such as computational cost and parameter sensitivity, their advantages make them an excellent choice for many machine learning problems.
- Understanding how SVMs work and how to tune their parameters can greatly improve their effectiveness in real world scenarios.
Frequently Asked Questions
Answer:
A Support Vector Machine (SVM) is a supervised machine learning algorithm used for classification and regression tasks. It works by finding the optimal boundary (called a hyperplane) that separates different classes of data. SVM focuses on maximizing the margin between data points of different classes. It is widely used for its accuracy and effectiveness in high-dimensional spaces.
Answer:
SVM works by identifying the best possible line or hyperplane that divides data into different categories. It selects support vectors, which are the closest data points to the boundary. These points help define the margin and improve model performance. The goal is to maximize the distance between classes while minimizing classification errors.
Answer:
There are mainly two types of Support Vector Machines: Linear SVM and Non-Linear SVM. Linear SVM is used when data can be separated with a straight line. Non-Linear SVM uses kernel functions to handle complex datasets. Common kernels include polynomial, radial basis function (RBF), and sigmoid.
Answer:
A hyperplane in SVM is a decision boundary that separates different classes of data points. In two dimensions, it is a line, while in higher dimensions, it becomes a plane or surface. The optimal hyperplane is chosen to maximize the margin between classes. This helps improve the model’s accuracy and generalization.
Answer:
Support Vector Machine offers high accuracy, especially in high-dimensional datasets. It works well with both linear and non-linear data using kernel tricks. SVM is memory efficient because it uses only support vectors. It is also effective in cases where the number of features is greater than the number of samples.
Answer:
SVM is widely used in image classification, text classification, and spam detection. It is also applied in face recognition, bioinformatics, and handwriting recognition. Due to its robustness, it is commonly used in financial forecasting and medical diagnosis. Its ability to handle complex data makes it highly valuable in real-world problems.

